Nested Learning, NL (嵌套學習)
動機
Nested Learning(NL)的提出建立在一個核心觀察:
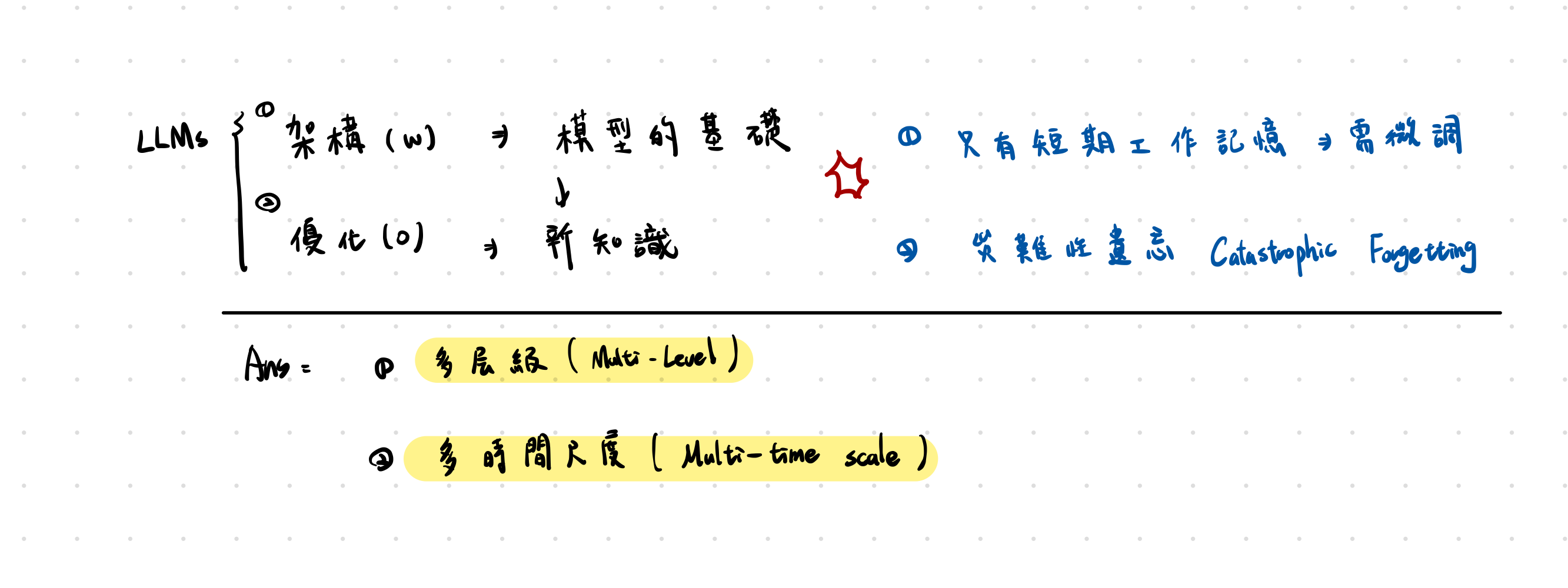
現有深度學習模型的「架構 vs 優化器」分離設計,使 LLM 在部署後幾乎無法再學習,並自然產生災難性遺忘。
We see a similar limitation in current LLMs: their knowledge is confined to either the immediate context of their input window or the static information that they learn during pre-training.
Nested Learning(NL)的提出,核心動機源自兩個面向:
- 現有 LLM 與深度學習框架的根本限制
- 人類大腦具備「多時間尺度、多層次記憶統合」的啟發
深度學習把「架構」與「優化」分離的設計方式,本身就是造成 LLM 靜態與無法持續學習的根因
NL 的目標不是單純改善 Transformer,而是重新定義模型:
⇒ 一組多層、嵌套、各自具有更新頻率的「學習系統」
LLM 的靜態性(Static Nature)
現有 LLM 的知識來源本質上只有兩種:
-
短期記憶(context window)
- 代表模型的工作記憶
- 只能參考,無法寫入
- 內容一旦滑出視窗就遺失
-
長期記憶(MLP/FFN 參數)
- 僅在預訓練時形成
- 部署後幾乎不再改變
- 新資訊無法寫入這些參數
一旦預訓練完成,模型的長期記憶(例如 FFN / MLP 參數)基本不再更新,只能體驗「短期現在」和「久遠過去」,而目前的 in-context learning 只是「短期工作記憶」,本質是不會寫入長期參數。
結果形成一種「類似失去海馬迴的患者」狀態:
- 當下理解能力正常
- 過去知識也存在
- 但無法把新的經驗寫入長期記憶
因此 LLM 的問題不只是「靜態」,更是:
⇒ 它們只能更新短期記憶,而無法執行大腦的 online consolidation(即時記憶鞏固)
⇒ LLM 完全缺乏 online consolidation(即時記憶鞏固)能力
核心問題:深度學習的結構性限制
現代深度學習遵循一個根深柢固的拆分:
- 架構參數(W):固定不變的計算圖
- 更新規則(Optimizer):外部操作,用於訓練期間更新 W
問題 1:所有長期記憶被壓縮在同一層級
模型必須把所有知識同時塞進同一套參數(MLP/Attention/Embedding),
不論是:
- 語言結構
- 世界知識
- 推論模式
- 任務技能
都全靠同一組 W 存放、同一頻率更新
問題 2:優化器不是模型的一部分
使用 Adam、SGD 等外部優化器意味著:
- 模型本體不知道怎麼更新自己
- 更新規則無法被學習
- 推論時沒有技術寫入長期記憶
- 沒有多層次的內在學習過程
這兩者被視為獨立模組,使模型無法:
- 自我修改(self-modify)
- 以不同時間尺度更新記憶
- 統一管理短期 / 中期 / 長期記憶
這造成兩個後果:
-
所有長期記憶都侷限在「單一層級的參數空間」
例如,MLP 層只能以單一時間尺度壓縮全部知識。 -
優化器(如 SGD、Adam)並不是模型的一部分,而是外部演算法
因此模型沒辦法「自己學會如何更新自己」,也無法在推論期間寫入長期記憶。
Nested Learning 直接挑戰這個傳統:模型 = 架構 + 優化器
模型與優化器兩者都是「記憶系統」,應該共同形成整體模型本體。
災難性遺忘(Catastrophic Forgetting)
災難性遺忘的根因不是「更新太快」,
而是現代模型所有參數都在同一時間尺度更新(single time-scale)
- 所以一旦你更新參數以適應新任務,就會覆蓋舊任務記憶
- 因為系統沒有「快、中、慢」不同記憶層級
- 記憶沒有多層轉換 / 鞏固過程
如果模型擁有 多層級(multi-level) 且 多時間尺度(multi time-scale) 的記憶模組,
就能像人腦一樣:
- 快速吸收新知(fast memory)
- 稍後整理(intermediate)
- 最終形成穩定長期記憶(slow memory)
Nested Learning 的觀點是:
⇒ 不同的參數模組應該具有不同更新頻率(multi time-scale),這樣才能同時保留長期知識,又能快速習得新資訊
- 新資訊可先暫存 → 整理 → 再寫入長期記憶
- 舊知識不會直接被覆蓋
- 模型才能真正具備 continual learning 能力
真正的洞見:深度學習只是「把嵌套學習扁平化」後的表象
深度學習其實是一種「錯誤的扁平化」
你以為深度學習是「堆疊 layer」 → 但這只是 Nested Learning 的「扁平展開」視圖
- 所有 layer 背後都有「隱藏的多層優化與記憶系統」
- 例如 Adam、Momentum、Linear Attention,都其實是「多層記憶系統」
- Transformer 只是把這些 multi-level systems 展成一個扁平的 layer stack
「Transformer 不是深,Transformer 是 多層記憶系統被壓成一層。」
NL 指出透過重新引入多層次 inner-loops(嵌套優化),模型就能自然具備持續學習能力
因此重新定義模型為:「一個具有不同更新頻率的階層式記憶堆疊(fast → mid → slow)」
HOPE(Hierarchically Optimized Processing and Encoding)
一個具有多層記憶、多時間尺度更新的序列模型
取代 Transformer,是 Nested Learning 的第一個具體架構
HOPE 的核心精神是:
把模型拆成多個「不同時間尺度」的記憶與處理層級,每層根據自己的「時間窗口」決定更新頻率,並把梯度/訊息以階層方式往下或往上傳遞。
HOPE 的主體是:
Input
└── Multi-level Memory Stack(CMS)
├── Level 1: Fast Memory (每步更新)
├── Level 2: Mid Memory (每 C2 步更新)
├── Level 3: Slow Memory (每 C3 步更新)
│ ...
└── Level k: Ultra-slow Memory
└── Output head
每一層都是一個小 MLP(或 linear),但更新頻率不同
Module 1 — Fast Memory(快速記憶層)
動機:
Transformer 的 attention 只能處理短期關係,它不會更新長期記憶也不會形成穩定技能
期望:
人類的大腦有 fast working memory(短期記憶),負責「立即響應」、快速適應新情境
⇒ 這層就對應 model 的「即時適應能力」
- 每個 token 來都會處理
- 每個 step 都會更新
- 快速適應最近出現的新 pattern
- 幾乎等同於 Transformer 裡 attention block 的角色,但可更新
⇒ 讓模型在無須重新訓練整個 network 的情況下,立刻擬合短期模式,允許模型「邊用邊學」(online learning)
Module 2 — Intermediate Memory(中速記憶層)
人類會:
- 先把資訊放工作記憶
- 再把重複重要的訊息往「中期記憶」搬移 (類似 synaptic consolidation)
HOPE 模仿的就是 短期 → 中期的記憶轉移過程
這樣的功效有:
- 以 中頻率 更新(每 C₂ 步)
- 對多步序列資料進行抽象
- 緩慢整合 fast 層累積的訊號
- 避免 fast 層記憶過載
- 開始形成「技能」「模式」級別的記憶(而非 token-level 記憶)
Intermediate 層:任務級別或段落級別的模式統整
Module 3 — Slow Memory(慢速記憶層)
對應人類的 systems consolidation(長期記憶),人腦在睡眠或長期重複過程中,把重要的知識寫入大腦皮質。
- 最低頻率更新(例如每 32 或 64 步)
- 接收來自 intermediate 層的已整理資訊
- 形成「穩定、持久」的記憶
- 作為 HOPE 的「長期知識庫」
⇒ slow memory 的存在使模型不會因學新任務而忘掉舊任務,避免 Catastrophic Forgetting 的核心
Module 4 — Hierarchical Update Mechanism(階層式更新機制)
Transformer 一次性更新所有參數,導致三大問題:
- 單一時間尺度
- 記憶扁平化
- 災難性遺忘
HOPE 的解法是每一層有自己的 optimizer + 自己的更新節奏:
Fast Memory: 每一步更新 ⇒ 學當下
Intermediate: 每 C₂ 步更新 ⇒ 學中期知識
Slow: 每 C₃ 步更新 ⇒ 寫入長期穩定知識
Reference
- Google 最新 AI 研究成果:嵌套學習 Nested Learning 是什麼? - INSIDE
- AI向人腦又近一步!Google發布嵌套學習、賦予LLM持續學習能力 | 鉅亨網 - 美股雷達
- Introducing Nested Learning: A new ML paradigm for continual learning
代表大腦不同記憶模組的更新速度完全不同:
快速更新:Working Memory / Online Learning
就像 LLM 的 attention,也像 few-shot ICL
- 即時理解
- 短期推論
- 提取上下文
中速更新:Synaptic Consolidation
- 海馬迴將短期記憶穩定化
- 記憶從暫時狀態轉為較持久狀態
慢速更新:Systems Consolidation
- 長期記憶的重組
- 長期知識寫入皮質(如語言、抽象概念)
資訊會依序通過多個不同層級的記憶模組,每層都以不同更新頻率加工一次
- Level 1:感知記憶(毫秒)
- Level 2:短期 / 工作記憶(秒)
- Level 3:中期記憶(小時)
- Level 4:長期記憶(天~年)