Batch Normalization
Google 於 2015 年提出了 Batch Normalization 的方法.
有一種方法是:在輸入數據時,通常都會先將 feature 做 normalize 後再進行訓練,可以加速模型收斂,而 Batch Normalization 就是指在每一層輸入都做一次 normalize。
方法
在訓練神經網路時,我們通常把資料切成很多 mini-batch(小批次),BN 會針對每個 mini-batch 的每個特徵,計算其平均值與標準差,然後進行正規化:
⇒ 將分散的數據統一
原本可是因為不同 mini-batch 的原始數據分佈可能非常不同,會導致網路訓練不穩定 → 經過正規化後,該 mini-batch 的輸入數據會被轉換成接近 平均值為 0、標準差為 1 的分佈 → BN 將每個 batch 的數據調整到類似的標準常態分佈 → 讓後續的層更容易學習
- 有助於減緩梯度消失以及解決 Internal Covariate Shift 的問題
- 可以加速收斂,並且有正則化的效果 (可以不使用Dropout)
:mini-batch 的平均值 :mini-batch 的變異數 :避免除以 0 的小常數
應用場景
Batch Normalization is used
when the "Error Surface (錯誤曲面) is too rugged(崎嶇)",
even if the error surface is convex, training is not easy.
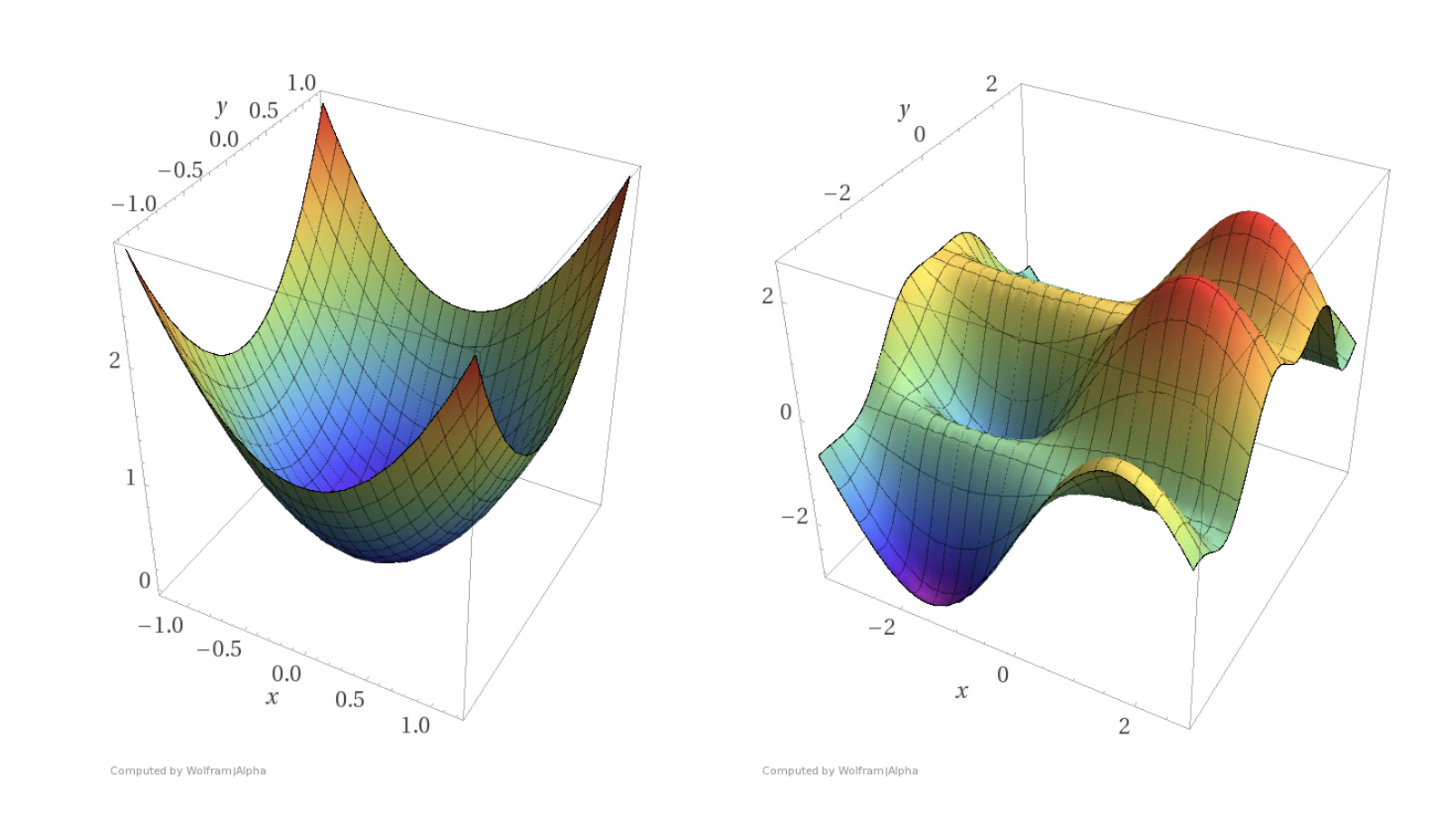
Fig: Left: a convex function. Right: a non-convex function.
It is much easier to find the bottom of the surface in the convex function than the non-convex surface. (Source: Reza Zadeh)
除了 Batch Normalization 之外,還有其他進階的優化方法,例如:
- Learning Rate (學習率)
- Adam
⇒ BN 只是其中一種提升訓練穩定性的方法
不過當我們用Optimizer(優化器)(例如 SGD、Adam)訓練模型時,理想情況下希望損失函數的 Error Surface (錯誤曲面) 是 Smooth(平滑) 的。
也因此 Batch Normalization 的作用 changes the landscape (使各個方向平順化) of the error surface to make it smoother in all directions.
- 減少梯度震盪
- 降低梯度爆炸或梯度消失的機率
- 提高訓練速度和穩定性
If the Error Surface (錯誤曲面) is flat,
it is less likely to encounter the so-called Critical Point (臨界點).
Feature Scaling (特徵縮放)
Works by rescaling the input features
→ so that they have 0 mean and 1 variance.
在深度神經網路中,若網路層數較多,通常會在其中插入 Batch Normalization 層,而這個過程本質上也是一種特徵縮放。
What are the advantage after Feature Normalization?
- Each "dimension has a mean of 0" and a "Variance of 1"
- To create a smoother error surface,
- one approach is to generate data that follows a normal distribution statistically(常態分佈)
⇒ 獲得上述,再做梯度下降可以收斂得更快、更好
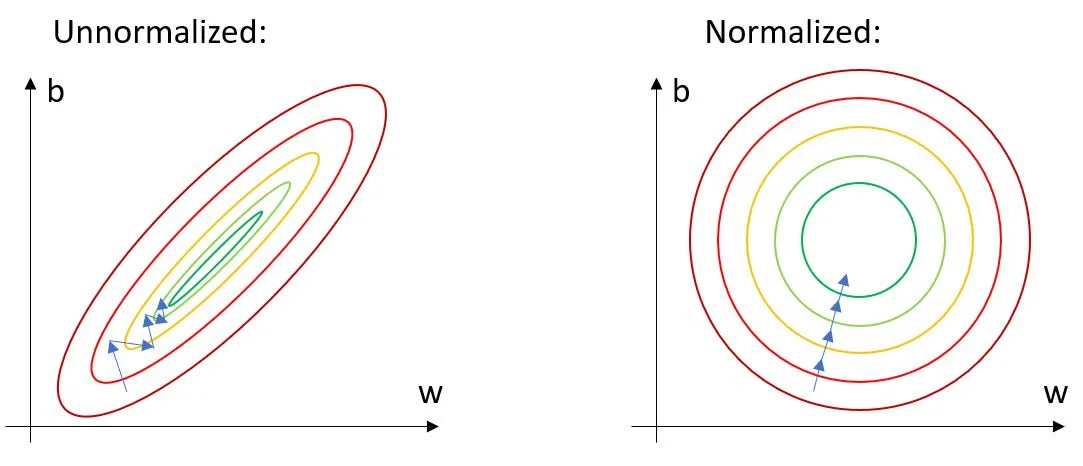
若沒有特徵縮放,誤差曲面可能非常崎嶇,
導致必須使用 非常小的學習率 才能避免過衝 (overshooting),
但過小的學習率又會導致收斂速度過慢,進而降低訓練效率。
How To Calculate the Mean and Standard Deviation
Fig: 當誤差曲面不平滑時,Learning Rate 選擇困難:
過大 → 過衝震盪;
過小 → 收斂緩慢。
Feature Scaling 可以緩解這個問題。
假設我們有一組資料
- 計算平均值:
- 計算標準差:
- 進行標準化 (Feature Normalization):
完成第一次 Feature Normalization 後,
因為每個元素在計算時會用到整個維度的 平均值 與 標準差,
因此同一維度中的所有元素會產生彼此關聯性。

Fig: 特徵縮放後,同一維度內的元素不再獨立,而是彼此關聯。
總結
- Feature Scaling 統一了不同特徵的尺度
- 讓 Error Surface 更平滑
- 改善 Gradient Descent 的穩定性與收斂速度
- 在深度神經網路中,Batch Normalization 也是特徵縮放的一種形式