ACL Ready - RAG Based Assistant for the ACL Checklist
一個基於檢索增強生成(Retrieval-Augmented Generation, RAG)的語言模型應用,用於協助作者完成 ACL 負責任 NLP 研究檢查表 (ARR Responsible NLP Research Checklist)。
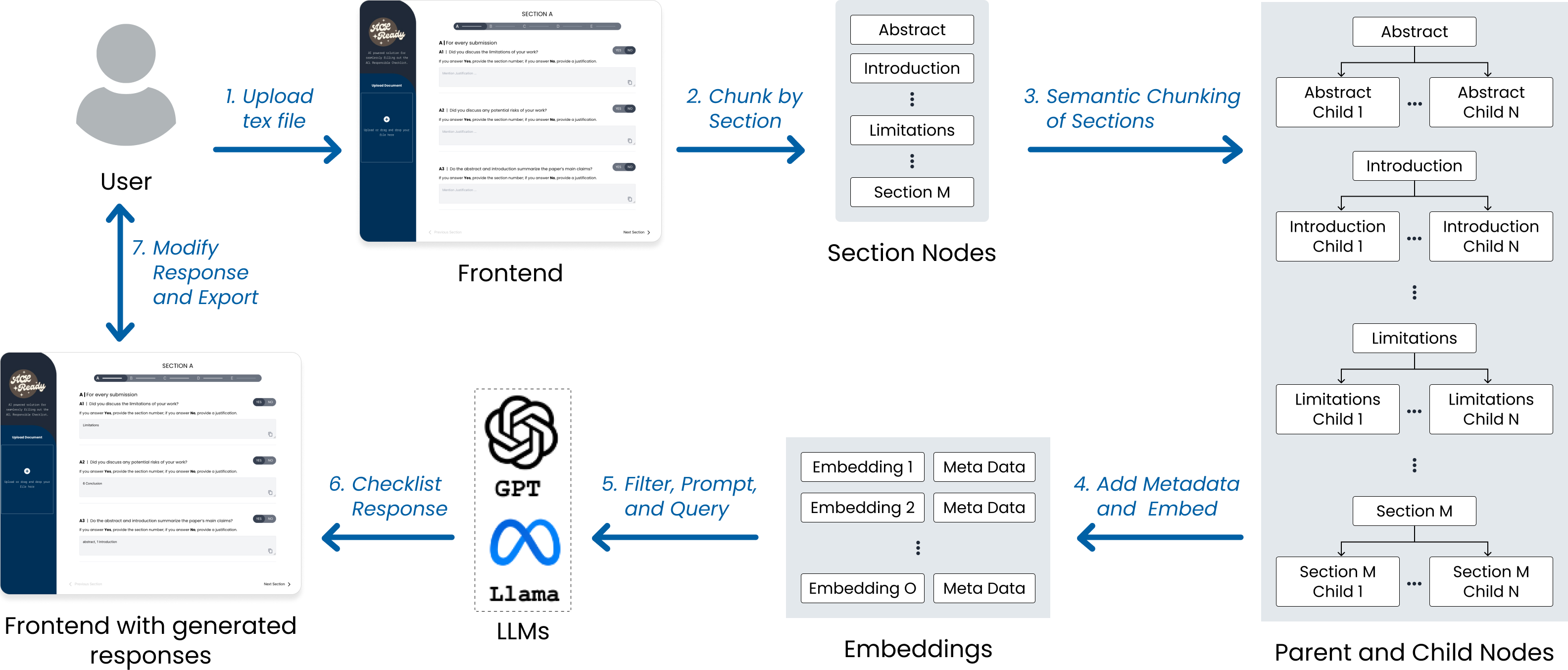
WorkFlow
- 使用者上傳 TeX 文件。
- 文件按章節進行分塊處理。
- 每個章節進一步進行語義分塊。
- 新增元數據並嵌入文本。
- 進行篩選、生成提示及查詢。
- LLM 生成檢查表回應並傳送至前端。
- 使用者檢查、修改回應並導出結果。
Parsing (解析)
上傳的是論文 TeX 文件:
- 移除所有註解和摘要前的內容。
- 刪除不必要的部分,例如感謝段落。
- 僅保留圖表的標題,刪除其他內容。
- 按順序對章節進行編號,模仿 LaTeX 編譯成 PDF 的結構。
Chunking (分塊處理)
- 每個章節作為獨立的節點分塊處理
- 每個節點新增元數據:
- 章節名稱
- 前一節的節點信息
- 下一節的節點信息
- 元數據便於篩選不相關的節點,提升查詢效率
- 語義分塊,根據句子嵌入的相似性,找出句子間的語義斷點,將節點細分為「父節點」與「子節點」
Embedding (嵌入)
- 嵌入技術:
- 使用預設的嵌入模型(例如
text-embedding-ada-002)。 - 或選擇開源模型(例如
m2-bert-80M-8k-retrieval)。
- 使用預設的嵌入模型(例如
- 節點過濾:
- 對於特定查詢,過濾掉不相關的節點。例如,針對「摘要與引言是否總結主要結論」的問題,只保留摘要和引言相關的節點。
- 檢索方法:
- 使用餘弦相似度進行檢索,從子節點中提取最相關的內容,並將其與父節點的內容結合後提供給語言模型(LLM)。