Reflexion - Language Agents with Verbal Reinforcement Learning
We propose Reflexion, a novel framework to reinforce language agents not by updating weights, but instead through linguistic feedback.
Reflexion 主要是透過語言反饋來強化 Agent, 而不是透過更新權重
背景
ReAct, SayCan, Toolformer, HuggingGPT
這類類型的研究已經證明可以基於 LLMs 核心建構自主決策代理的可行性,主要是透過 LLMs 生成文本在環境中執行「操作」。
缺點?
由於傳統的強化學習與梯度下降優化方式計算成本極高,因此目前主要依賴上下文示例(Context)進行學習。
Reflexion
⇒ 透過反思,使用語言強化幫助 Agent 從失敗中學習
方法
- 透過環境回饋的文字總結 (可以是二元回饋:成功/失敗),作為下一回合 LLMs 的額外上下文
- 透果自我反思作為「語義梯度」,提供具體方向
- 類似於 Few-Shot Learning
挑戰
- 辨識模型錯誤的來源(信用分配問題,credit assignment)
- 產出具可行性的改進建議
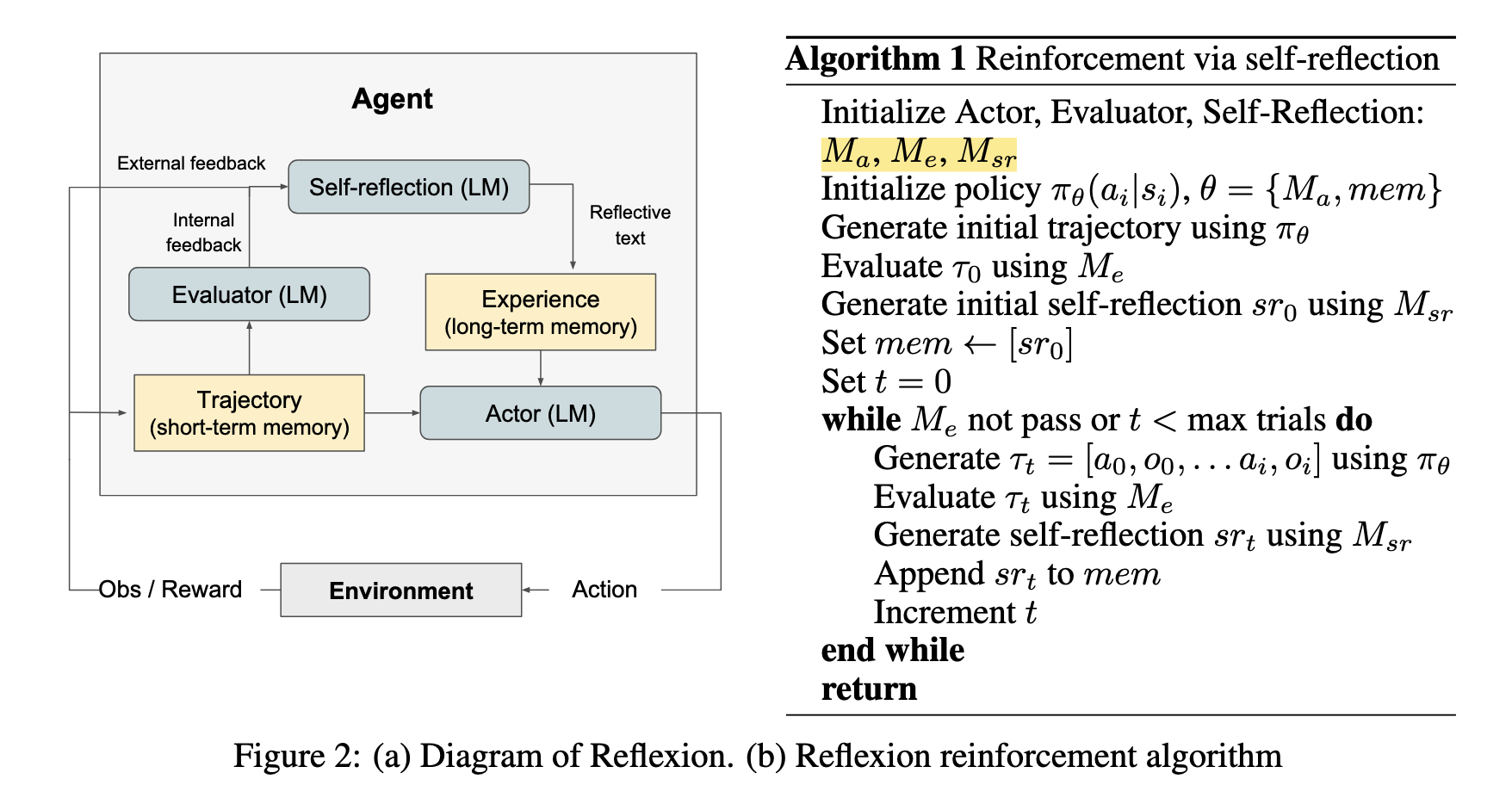
Actor
Actor 透過特定提示 (prompting) 來生成對應於狀態觀察的文本與行動類似於傳統策略學習 (policy-based RL),Actor 會在時間步 t 透過當前策略
各種 Actor:
- Chain of Thought (CoT):促進逐步推理能力。
- ReAct:結合推理與行動的 LLM 方法。
Self-reflection 的 記憶 (mem) 組件 提供 額外的上下文資訊,幫助 Actor 在學習過程中利用歷史數據
Evaluator
評估 Actor 產生的輸出好壞,具有挑戰性:
- 在語義空間定義 有效的價值與回饋函數 (value & reward functions)
- 計算 Reward Score 來反映特定任務的表現
不同類型的 Evaluator:
- 推理 (Reasoning) 任務
- 使用 **精確匹配 (Exact Match, EM) ** ,確保輸出與預期解答高度一致
- 決策 (Decision-Making) 任務
- 採用預定義的啟發式函數,根據具體評估標準打分
- 程式設計 (Programming) 任務
- 探索不同評分方式,包括使用另一個 LLM 作為 Evaluator,來為決策與程式任務生成回饋
探索不同的評分策略,分析各種方法的有效性與適用範圍
Self-Reflection
負責生成語言化的自我反思 (verbal self-reflections),為未來試驗提供回饋
輸入:
- 稀疏回饋信號(如二元成功/失敗標記)
- 當前軌跡 (trajectory)
- 持久記憶 (mem)
輸出:生成細緻的反思回饋,存入記憶 (mem) 供未來決策參考。
可能導致錯誤的
代理應改變策略,選擇不同的