SGP-TOD(Schema-Guided Prompting for Task-Oriented Dialog systems)
任務導向對話系統 Task-Oriented Dialog Systems, TOD
以大型語言模型(LLMs)為基礎,透過 Schema-Guided Prompting 來實現 TOD 而不需要額外訓練數據(Zero-Shot)
三個核心組件
- LLM(大型語言模型):處理與使用者的互動
- Dialog State Tracking (DST) Prompter
- 幫助 LLM 追蹤對話狀態,確保系統理解使用者的需求
- Policy Prompter
- 指導 LLM 根據對話策略(Dialog Policy) 產生適當的回應
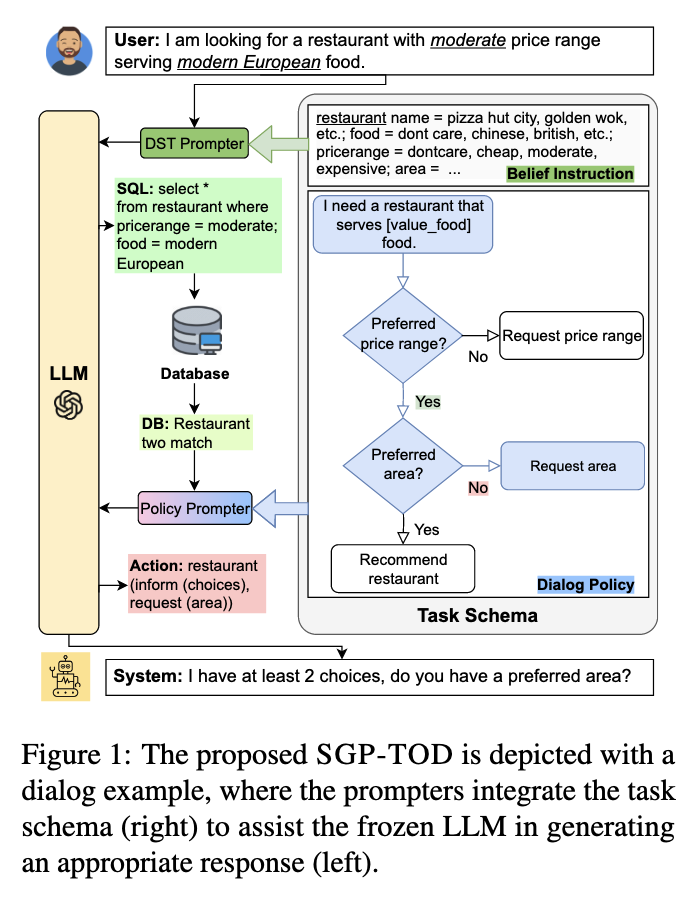
Schema 是一個結構化的規則,用來引導 LLM 進行對話
- Slots(槽位)
- 例如 restaurant_name、food_type、price_range
- Dialog Flow(對話流程)
- 定義如何引導使用者,例如先詢問 location,再詢問 price_range
- Dialog Acts(對話行為)
- 如 request_info、inform、confirm
Prompters(提示詞控制)
- DST Prompter(對話狀態追蹤)
- 幫助 LLM 追蹤當前對話狀態
- Policy Prompter(對話策略)
- 指導 LLM 根據 Schema 產生合適的回應
Zero-Shot Learning(零樣本學習)
- 不需要訓練數據,只要修改 Schema,就能適應新的對話領域
vs. SGD(Schema-Guided Dialog
| SGP-TOD(Schema-Guided Prompting) | SGD(Schema-Guided Dialog | |
|---|---|---|
| 模型使用方式 | 直接使用固定 LLM,不需微調 | 需要微調對話系統(Fine-Tuning) |
| 對話狀態追蹤(DST) | 透過 DST Prompter + Belief Instruction 讓 LLM 解析 | 透過 DST 模型 追蹤 |
| 策略學習 | 透過 Policy Prompter + Policy Skeleton 控制回應 | 透過 策略學習模組 訓練 |
| 數據需求 | 不需要標註數據,只需 Schema | 需要大量標註數據 |
| 適應新任務的方式 | 修改 Schema 即可適應新任務 | 需要新數據 & 重新訓練 |
| 適合的應用場景 | 快速原型開發、動態變更任務 | 長期穩定應用(如企業客服) |