向量資料庫 (Vector Database)
向量資料庫說明
實現 RAG, Retrieval-Augmented Generation 時需要選擇適合的向量資料庫,向量資料庫是一種專門設計用來儲存、管理和檢索高維度向量資料的資料庫系統。
向量資料庫功能是儲存嵌入向量及其元數據,利用各種索引和近似最近鄰(ANN)方法高效檢索與查詢相關的文檔。
主要目的是自然語言處理和計算機視覺中,資料(如文字、圖像)經常被轉換為向量表示,以捕捉其語義或特徵。
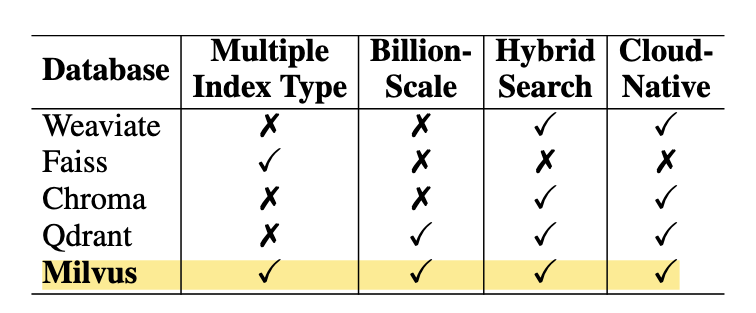
以下是常見的向量資料庫:
- Weaviate
- 提供靈活的 GraphQL API,方便查詢
- 可能需要較多資源配置
- Faiss
- 由 Facebook AI Research 開發,專注高效相似度搜索
- 主要作為庫使用,缺乏完整的資料庫功能,如持久化和即時更新
- Chroma
- 適合快速原型開發
- 功能相對簡單,可能無法滿足複雜應用需求
- Qdrant
- 高性能的向量資料庫,支援即時資料更新
- 社群和生態系統較小,資源可能較少
- Milvus
- 功能最完善,支援多種索引類型和相似度計算方法
- 活躍的開源社群,提供豐富的資源和支援
- 學習成本相對較高
評估標準
- 多索引類型(Multiple Index Types)
- 根據不同的數據和需求,使用不同的搜尋方式來提升搜尋效率和準確度
- 例如,對於文字數據,可能用傳統的關鍵字搜尋,而對於圖片或語音,則使用向量搜尋。
- 億級規模支持(Billion-Scale Vector Support)
- 處理大規模數據集(如 LLM 應用)的必要功能。
- Hybrid Search (混合搜尋)
- 結合向量搜尋(基於內容相似性搜尋)和傳統的關鍵字搜尋,提高檢索準確性,無論是找到與某個詞完全匹配的內容,還是找到與某個詞相關的相似內容
- 雲原生特性(Cloud-Native Capabilities)
- 能夠很好地與雲平台(如AWS、Google Cloud等)協同工作,實現自動擴展、靈活調整以及容易管理
aclanthology.org/2024.emnlp-main.981.pdf
通常會倚賴 Embedding Model 將其存在 Vector Database...