Context Engineering
Context Window(上下文窗口)是什麼?
- Context = 丟給模型看的所有東西:問題、背景說明、工具清單與輸出、對話紀錄…都算。
- Context Window = 一次能塞進去的上限(用 token 計)。
- 粗算方式(英文):
1 token ≈ 0.75 個英文單字 ≈ 4 個字元100 tokens ≈ 75 words1–2 句 ≈ 30 tokens1 段落 ≈ 100 tokens
- What are tokens and how to count them? | OpenAI Help Center
- 粗算方式(英文):
常見模型的可塞容量(簡表)
- Gemini 2.5 Pro:1,000,000 tokens
- GPT-5(API):輸入 272K(總長 400K,輸出/推理 128K)
- DeepSeek-V3 / V3.1:128K
- Claude(Anthropic):一般 200K、Enterprise 500K;Sonnet 4 提供 1M
視窗很大,但不是無限大;而且不同產品線/方案上限不一樣
# 為什麼不能把資料「一次全丟」?
- 視窗有限:塞滿會截斷,前面內容直接不見。
- 雜訊干擾:沒篩選會讓模型抓不到重點,回答變含糊。
- 成本跟 token 綁:token 越多越花錢,做產品一定要控量。
Context Engineering
不改模型本體,針對模型輸入進行優化,只改「模型看到什麼、何時看到」
⇒ 讓答案更準、更穩、更省
設計模型輸入內容這些必須成因來自兩點:
- 模型已經夠強:多半不是「模型不會」,而是「你沒給對上下文」
- Agent 很吃上下文:工具結果、瀏覽紀錄、執行日誌會快速塞滿視窗,上下文工程就變成決勝點
- Model Context Protocol, MCP
- 一個讓模型安全連到外部資料/工具的開放協定
- 資料端像 MCP Server、應用端像 MCP Client
- Model Context Protocol, MCP
1) 保存 / 寫(Write / Persist)
- 把「常用、會重複」的資訊「先整理/摘要」,存到記憶庫或向量庫;要用再取
- 例:ChatGPT 的 Memory(可開關、可查/刪)
- 心法:「存」≠「每次全塞」;要用才拿出來。
⇒ 但是該怎麼精準找到資訊?
2) 選擇(Select)
- 靜態選擇:每次必帶的規則/原則/安全條款(像
RULES.md、CLAUDE.md)。 - 動態選擇:依問題只取最相關的 N 段與必要工具
- 目標:給關鍵的幾頁,而不是整本書
3) 壓縮(Compress)
- 對 長對話、工具輸出、冗長上下文 做 摘要/去冗,保留證據與關鍵改動,釋放視窗。
- 例:Claude Code 視窗>95% 會自動 auto-compact,可自訂壓縮重點
4) 隔離(Isolate)
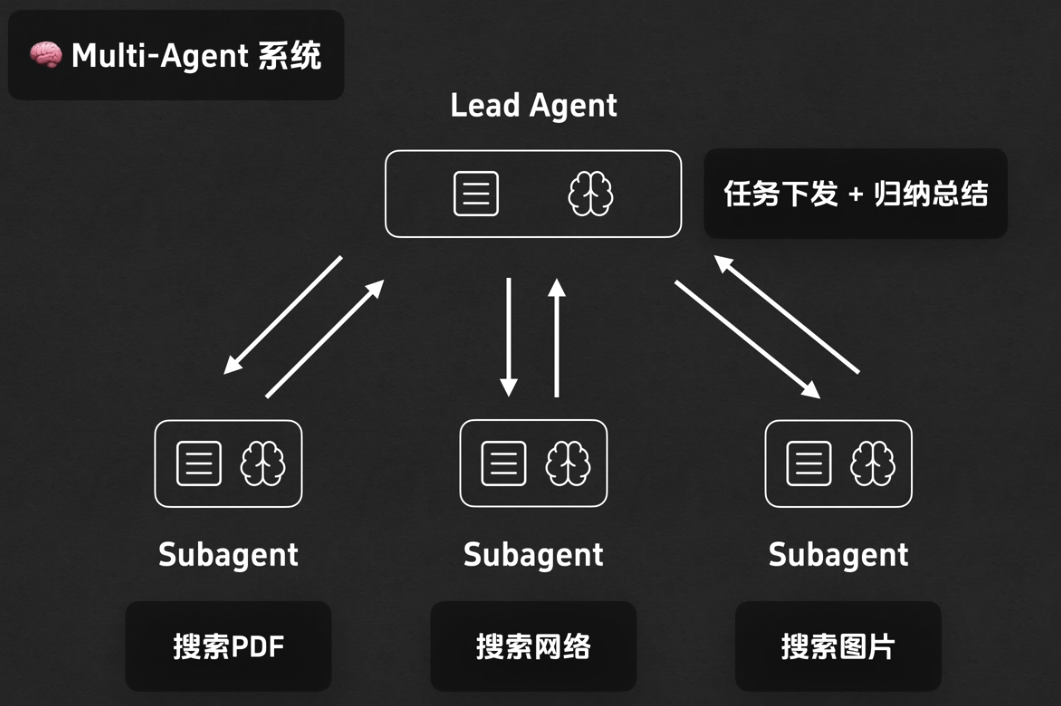
- 多代理(Multi-Agent)分艙:
- 每個子代理有自己的上下文與工具,互不干擾;
- 由 Lead/Orchestrator 統整
- 好處:並行探索、降低互相污染;代價:協作成本與 token 用量上升
Context Engineering
Context Engineering:概念与技术实现深度解析 - YouTube