BEVERS - A General, Simple, and Performant Framework for Automatic Fact Verification
Abstract
這篇 BEVER 主要研究自動事實驗證,針對 FEVER 數據集有很好的表現。框架使用標準的文檔檢索、句子選擇和驗證主張分類方法
BEVER 在 FEVER 的評分和標籤準確性方面優於所有已知系統。在另一個驗證的數據集 Scifact 上也都達到了最高標準準確性。
- Introducing BEVERS, a top-performing baseline for Fact Extraction and Verification (FEVER) (Thorne et al., 2018)
- Uses standard techniques for document retrieval, sentence selection, and claim classification.
- Outperforms all known systems in FEVER score and label accuracy.
- Also excels in label accuracy on another dataset, Scifact.
Introduction
FEVER數據集簡介
由於近年來線上假信息(misinformation)的盛行,特別是在COVID-19大流行期間,自動事實驗證變得越來越重要。
FEVER數據集是一個廣泛使用的數據集,專門用於自動事實驗證。
數據集包含185,445個聲明(claims)和超過5,000,000篇Wikipedia文章作為驗證語料庫,從這些頁面中選擇相關的句子,根據這些句子和聲明來判斷聲明是被支持、被反駁還是沒有足夠的信息。
- FEVER is a leading dataset for automated fact-checking with 185,445 claims.
- Uses a 2017 Wikipedia dump with 5M+ articles for verification.
- Claims are categorized as supported, refuted, or inconclusive.
事實驗證的基本流程,對於每個聲明,任務包括三個主要步驟:
- 找到相關的Wikipedia頁面
- 從這些頁面中選擇相關的句子
- 根據這些句子和聲明來判斷聲明是被支持、被反駁,沒有足夠的信息。
主要評估指標:FEVER分數
FEVER分數是評估系統性能的主要指標,它要求預測的標籤必須是正確的,並且至少有一個正確的證據被檢索出來。
Main Metric: FEVER Score
- The FEVER score requires both that the predicted label is correct as well as at least one piece of correct evidence being retrieved as predicted evidence.
Baseline fact Extraction and VERification System (BEVERS).
基線事實提取和驗證系統
許多近期的研究已經審查了流程的各個部分,並對基線方法做出了創新的改進。但這個系統不是對基線流程進行創新改進,而是調整這些組件的每一個部分以確保最大的性能。
- Focuses on tuning existing components for maximum performance, rather than introducing novel improvements.
在FEVER上的實驗結果
系統在FEVER的盲測數據集上達到了最先進(SOTA)的性能。
基線流程應用於另一個流行的事實驗證數據集Scifact時,系統在該數據集上也實現了最高的標籤F1分數。
- Despite its relative simplicity yet achieves state-of-the-art.(SOTA)
- Also tops in label F1 score on Scifact (Wadden et al., 2020) dataset.
跟隨先前工作但進行優化
BEVERS沒有對基線流程進行創新改進,而是對每個組件進行了調整以確保最大性能。具體來說,它的流程與使用Transformer模型的第一個FEVER系統(由Soleimani等人於2020年提出)相似。
Optimized Existing Work
Fine-tuned based on prior approaches for peak performance.
- Similar to early Transformer-based FEVER systems by Soleimani et al. (2020).
Related Work and Methods
Document Retrieval
Related Words
TD-IDF
初始的FEVER基線使用了標準的TF-IDF文檔檢索模型。
- Initial FEVER baseline used standard TF-IDF for document retrieval.
NER
Hanselowski等人(2018)通過使用命名實體識別(NER)從聲明文本中提取查詢詞,並使用這些查詢詞對WikiMedia的API2進行查詢,從而對此進行了改進,該API2已經被廣泛使用。
- Hanselowski et al. (2018) improved with NER-based (named entity recognition) queries via WikiMedia's API2.
結合傳統IR方法和NER
如Stammbach(2021)和Jiang等人(2021),使用了傳統的信息檢索方法與Hanselowski等人(2018)的NER方法的組合。
Combining traditional IR methods and NER
- Stammbach (2021) and Jiang et al. (2021) blended traditional IR with Hanselowski's NER method.
Method
BEVERS is similar to past methods but has some changes.
- Blended traditional IR with Hanselowski's NER method.
- BEVERS employs a similar setup but utilizes a fuzzy string search for document titles, rather than relying on WikiMedia's API.
TD-IDF
文檔和標題建立單獨的表示。
首先,分別 optimize 標題和文檔的參數。
其次,讓系統根據單獨根據標題找出一半的文件,根據這些標題找出至少一半的搜索結果,這樣的好處是讓系統更重視標題名稱。
TD-IDF
- For BEVERS TF-IDF, the system build separate representations for documents and titles.
- Separate reps for documents and titles, two reasones.
- First, fine-tune title and document parameters separately.
- Second, forces system to prioritize titles by retrieving half docs based on titles.
Sentence Selection
在檢索文檔之後,下一步是對證據進行評分並為聲明的預測證據形成一個排名。
這部分主要著重於如何從檢索到的文檔中選擇相關的句子作為預測的證據。
點對點排名(Point-wise Ranking)
BEVERS採用了最簡單的點對點排名方法,其中每個句子都單獨地與聲明進行比較和評分。
- The simplest approach to doing this is referred to as 'point-wise' ranking, in which each sentence is scored individually against the claim.
- This is the approach utilized by most systems
二元與三元分類(Binary and Ternary Classification)
BEVERS考慮了兩種情況:將任務視為二元分類任務和三元分類任務。
在二分類的情況下,標籤集僅包括「相關」和「不相關」,其中「相關」的softmax分數用於排名。
在三分類的情況下,我們使用「駁斥」、「信息不足」和「支持」作為標籤,並使用1減去「信息不足」的softmax分數進行排名。
- Task as binary and ternary classification.
- Binary labels: RELEVANT, IRRELEVANT.
- Use RELEVANT softmax for ranking.
- Ternary labels: REFUTES, NOT ENOUGH INFO, SUPPORTS.
- Use 1−NOT ENOUGH INFO softmax for ranking.
文檔檢索方法中檢索的文檔中隨機抽樣句子作為負樣本
在二分類情況下,這些隨機的負樣本被分配到「不相關」的標籤類別,所有真實的證據被分配到「相關」。
在三分類情況下,負樣本被分配到「信息不足」,而真實的證據則被分配到其相應的標籤,即「駁斥」和「支持」。
- Negative samples from the document retrieval
- Binary: Negative samples as IRRELEVANT, true evidence as RELEVANT
- Ternary: Negative samples as NOT ENOUGH INFO; true evidence as REFUTES/SUPPORTS."
重新檢索(Re-retrieval)
Evidence-based re-retrieval 是一種在句子選擇過程中使用的方法,旨在改進初步檢索到的證據。這個過程利用了FEVER數據集中每個句子的超鏈接信息。
為什麼這麼做?
- 提高準確性:這個過程可以提高檢索到的證據的準確性和相關性。
- 多跳檢索(Multi-hop Retrieval):這種方法與 Stammbach(2021)的多跳檢索非常相似,允許系統從初始檢索的句子中找到的超鏈接提取額外的文檔。
怎麼做?
- 初始預測證據(Initial Predicted Evidence):首先,從一個或多個文檔中檢索一組初始的預測證據。
- 超鏈接信息(Hyperlink Information):這個過程利用初始句子中找到的超鏈接信息來提取額外的文檔。
- 額外文檔(Additional Documents):從這些額外的文檔中檢索句子。
- 評分和結合(Scoring and Combining):這些額外文檔中的句子會被評分並與初始句子結合,以形成一個最終的預測證據集合。
- 排名機制(Ranking Mechanism):如果一個句子
是由於 中的一個超鏈接而被檢索的,那麼最終的檢索分數會是 )。
Evidence-based re-retrieval.
- Initial Predicted Evidence: Initially, a set of predicted evidence is retrieved from one or multiple documents.
- Hyperlink Info: Hyperlinks found in the initial sentences are used to extract additional documents.
- Additional Documents: Sentences are retrieved from these extra documents.
- Scoring & Combining: Sentences from additional documents are scored and combined with initial sentences to form a final evidence set.
- Ranking Mechanism: If a sentence
is retrieved due to a hyperlink in , the final retrieval score is ).
Evidence-based re-retrieval.
- FEVER dataset has sentence hyperlinks.
- Initial evidence used to extract more docs via hyperlinks.
- Additional sentences scored and mixed for final top 5 evidence
Different with Multi-Hop Retrieval and BEVERS
BEVERS的方法與Stammbach(2021)的"multi-hop retrieval"非常相似,但在結合兩組句子時有細微的差異。
- Similar to Stammbach’s (2021) 'multi-hop retrieval,' but differs in sentence combining.
Multi-Hop Retrieval(多跳檢索)
- 目的:這個過程旨在改進初步檢索後的證據(evidence)質量和相關性。
- 工作原理:
- 初始檢索(Initial Retrieval):首先進行一輪的檢索,獲得與主張(claim)相關的初始句子(sentences)。
- 超鏈接信息(Hyperlink Information):這些初始句子中可能包含超鏈接,指向其他相關的文檔。
- 額外檢索(Additional Retrieval):通過這些超鏈接,進行第二輪(或更多)的檢索,獲得更多的句子。
- 結合和評分(Combining and Scoring):這些新檢索到的句子會與初始句子一起被評分和排名。
這是一種由Stammbach(2021)提出的方法。它也使用超鏈接信息來進行額外的文檔檢索。Stammbach設定了一個預定義的閾值,以防止重新檢索的證據將初始檢索的證據推出前5名。
- Stammbach uses a threshold to keep re-retrieved evidence from displacing initial top 5
BEVERS
BEVERS發現,簡單地將兩組句子組合在一起實際上會降低召回率,因為重新檢索的證據有時會將初始檢索的相關證據推出前5名。
- Combining both sets can lower recall; re-retrieved evidence might displace initially relevant ones.
細節調整
為了防止重新檢索的證據將初始檢索的相關證據推出前5名,BEVERS對重新檢索的句子進行了分數調整。
如果某個證據
也允許重新檢索到的證據的得分與負責其檢索的最初證據的得分成正比。
- Final score =
if is linked from . - This scaling prevents re-retrieved evidence from displacing top 5 initial evidence
這個"evidence-based re-retrieval" 方法允許BEVERS在保留初始檢索結果的優質性的同時,還能進一步提高句子選擇的效果。
性能(Performance)
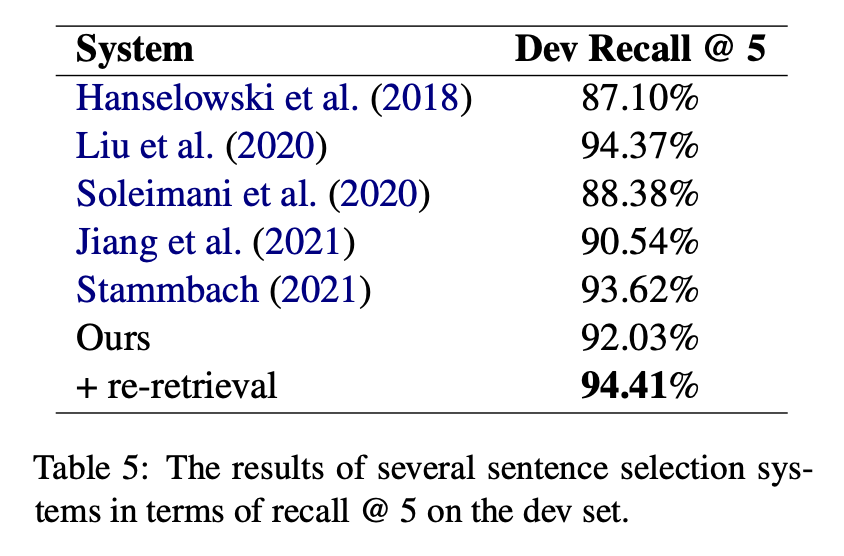
根據論文中的實驗結果,BEVERS的句子選擇系統在開發集上的召回率(recall @ 5)表現優於所有先前的系統。
Claim Classification
這一部分主要著重於如何對每個聲明進行分類,即判斷它是被支持、被反駁,還是沒有足夠的信息。
BEVERS使用了多種不同的模型和方法來進行聲明分類。
Related Works
多樣性的方法
最近在聲明分類方面有多種不同的方法,包括使用Transformer模型和圖神經網絡。
- Various recent methods for statement classification include Transformers and Graph Neural Networks.
初始的Transformer方法
由Soleimani等人(2020)提出,這個方法對每一對聲明和證據進行了預測,並使用一組簡單的規則來整合不同證據片段的標籤。
- Soleimani et al.'s (2020) Transformer model used simple rules to aggregate labels for each claim-evidence pair.
圖神經網絡
Liu等人(2020)和Zhong等人(2020)探討了使用圖神經網絡作為聲明分類模型,顯示出由於能夠聚合不同證據片段的信息而優於僅使用Transformers。
- Studies show Graph Neural Networks (Liu, Zhong 2020) improve claim classification over Transformers by better evidence aggregation.
最近的改進
更大的Transformer模型和將所有證據句子連接在一起已經顯示出進一步的改進。Jiang等人(2021)使用了T5模型,而Stammbach(2021)使用了DeBERTa V2 XL MNLI。
- Bigger Transformers and concatenated evidence improve results.
- Jiang et al. (2021) using T5 (Raffel et al., 2020)
- Stammbach (2021) using DeBERTa V2 XL MNLI (He et al., 2021).
Method
對於我們的方法,我們會考慮三種情況:單例(singleton)、連接(concatenated)和混合(mixed case)的預測。
使用文檔選擇和句子選擇來為每一個主張的訓練預測一個前五的證據集合。
- Predictions for singleton, concatenated, and mixed cases.
- Top-5 evidence predicted for each claim in training.
在單例情況下,我們使用⟨主張,證據⟩對作為輸入,為每一個證據片段生成一個預測。
在連接(concatenated)情況下,我們將所有證據連接在一起,並基於⟨主張,證據1,證據2,...⟩來形成輸入。
在單例情況下,輸入是一個5 × 4矩陣(5個證據,3個softmax分數和一個檢索分數)。
- Singleton case uses ⟨claim, evidence⟩ pairs for each prediction.
- Concatenated case uses ⟨claim, evidence1, evidence2, ...⟩ as input.
- Singleton input: 5x4 matrix with 5 evidence and 3 softmax plus 1 retrieval score.
對於混合(mixed)方法,我們將單例(singleton)方法和連接(concatenated)方法混合在一起。
在混合情況下,輸入是一個6 × 4矩陣(包括額外連接的輸入softmax分數和檢索分數,這是從5個證據的平均檢索分數計算出來的)。
- Mixed approach combines singleton and concatenated methods
- Mixed input: 6x4 matrix, includes averaged retrieval and concatenated softmax scores.
對於單例和混合方法,我們對每一個主張都有多個預測。
為了將這些聚合成單一分數,我們使用每個預測的softmax分數和檢索分數,並在這些輸入上訓練一個梯度提升分類器(Friedman, 2001)以產生單一預測。
- To aggregate scores, we train a gradient boosting classifier (Friedman, 2001) on softmax and retrieval scores for a single prediction.
Experimental Setup
BEVER 改進的主要來源是對每個組件進行超參數調整。
識別超參數和潛在的值,並執行網格搜索以找到每個組件的最佳配置。
- BEVER attributes system improvements to hyperparameter tuning.
- Grid search identifies optimal hyperparameters for each component.
TD-IDF
使用 SciKit Learn(Pedregosa 等人,2011)的 TF-IDF 表示法。
模糊字符串搜索是使用 Sqlite 的 spellfix1 虛擬表來實現的。
- Use SciKit Learn’s (Pedregosa et al., 2011) TF-IDF.
- Fuzzy search via Sqlite's spellfix1 table.


句子選擇超參數調整
選擇超參數調整被分為兩個部分
- 首先,優化選擇的負樣本數量以及用於排名的二進制與三進制類。
- 使用初始設置的最佳選擇,調整學習率和標籤平滑。
selection hyperparameter tuning is split into two sections.
- First, we optimize the number of negative samples selected as well as binary vs ternary classes for ranking.
- Using the best selection from the initial setup, we tune the learning rate and label smoothing.

其他細節:
由於FEVER數據集沒有為NOT ENOUGH INFO claims提供證據,因此必須使用負樣本來生成這些訓練示例。
Results
Sentence Selection
主要指標: 使用recall @ 5作為主要的評估指標。這是因為當計算FEVER分數時,該指標僅考慮最多5個預測的證據。
與其他系統的比較: 在開發集上,本系統的句子選擇性能超過了所有先前的系統。這一點特別值得注意,因為即使相對於使用更大模型的系統(如Jiang et al. 2021的T5方法),本系統仍然表現出色。
特殊觀察: 包括基於證據的重新檢索(evidence-based re-retrieval)可以顯著提高recall指標。
- The primary metric used is recall @ 5.
- Despite a smaller model and pointwise scoring, our results compare with Jiang et al.’s (2021) T5 and Stammbach's context methods.
- Separating initial and re-retrieval results, we see major recall improvement, aligning with Stammbach's findings.
Claim Classification
通過混合"單例(singleton)"和"串聯(concatenate)"的方法,系統獲得了一點小幅度的改進。儘管這種改進不是顯著的改善來源。
單例方法的局限和表現:
單例方法不能模擬需要多跳證據(multi-hop evidence)的聲明。
儘管如此,它仍然表現得相當好。
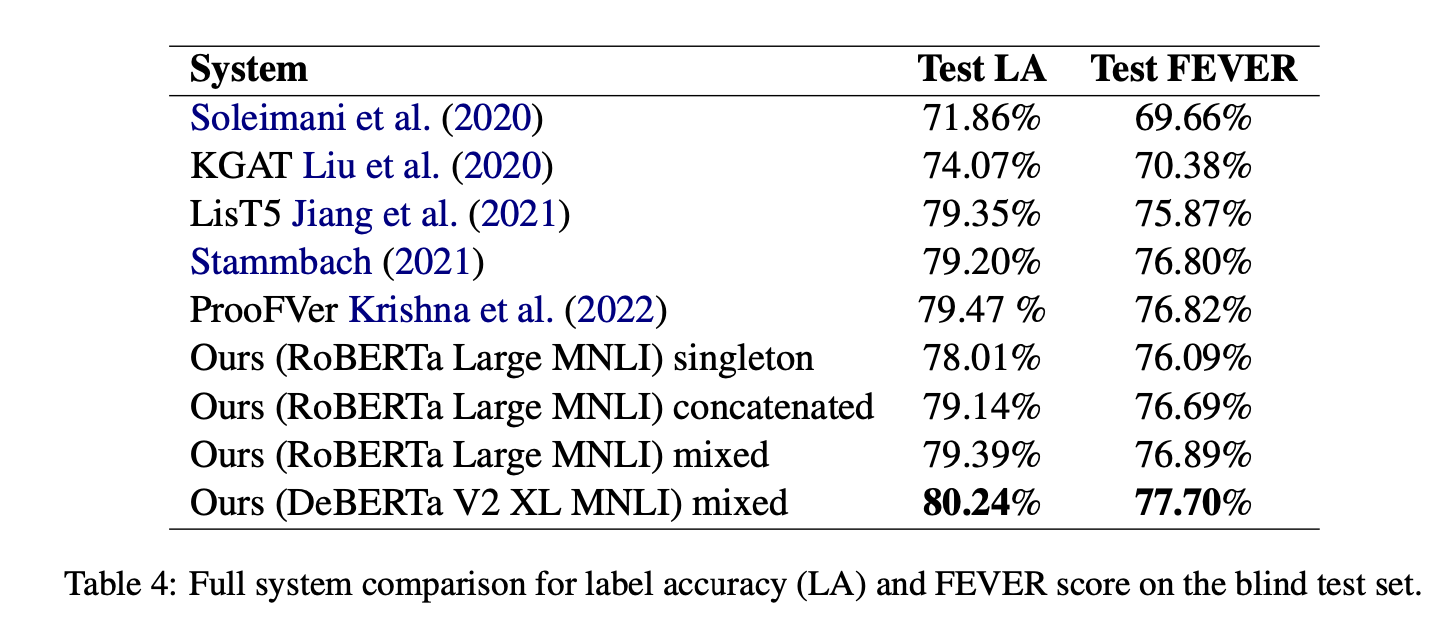
模型大小和性能
該系統使用的是一個相對較小的模型,具有3億個參數,與T5的30億和DeBERTa V2 XL MNLI的9億相比。
儘管模型較小,但其RoBERTa Large MNLI系統在所有已發表的系統中達到了最高的FEVER分數。
DeBERTa V2 XL MNLI的使用
當使用DeBERTa V2 XL MNLI和混合方法時,該系統在盲測集(blind test set)上達到了所有系統中最高的標籤準確性和FEVER分數,無論是已發表還是未發表的。
- Mixing singleton and concatenate methods yields minor gains.
- Singleton performs well, even without multi-hop capability.
- Smaller RoBERT Large MNLI model outperforms larger T5 and DeBERTa systems in FEVER score
- Our mixed approach with DeBERTa V2 XL MNLI tops all systems in label accuracy and FEVER score on the blind test.
Beyond FEVER: Scifact
數據集結構
SciFact數據集與FEVER數據集在結構上非常相似。不同之處在於,SciFact的語料庫是由科學文章組成的。
一個困難的來源是,主張經常用非專業的語言來表達,這與科學文章中主題的呈現方式在形式上可能有很大的不同。
- Claims in lay terms contrast sharply with scientific articles, posing a challenge.
- The smaller dataset has just 1,409 claims and 5,183 abstracts.
- This pipeline closely follows FEVER, omitting only fuzzy string search
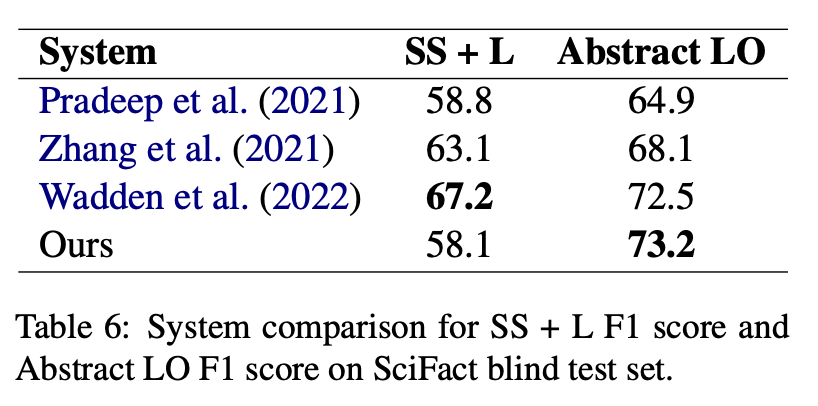
性能和比較
報告的指標是句子選擇+標籤(SS + L)和僅摘要標籤(Abstract LO),這些指標大致對應於FEVER的分數和FEVER的標籤準確性。
從SS + L指標可以看出,我們文件檢索系統的簡單性似乎限制了整個系統的表現。
儘管如此,在Abstract LO指標上,我們的系統在盲測集上獲得了最高的F1分數,超越了該指標上的最佳狀態。
- The metrics reported are sentence selection + label (SS + L) and abstract label only (Abstract LO).
- In the SS + L metric, BEVER's simple retrieval limits performance.
- However, BEVER tops the F1 score in Abstract LO, beating the SOTA.
Conclusion
- Introduction: Introduced BEVERS for FEVER and SciFact datasets.
- Similar Structure: Builds on previous works like Soleimani et al., 2020.
- Performance: Achieved SOTA in FEVER and top label accuracy in SciFact.
- Key to Success: Focused on hyperparameter tuning and error analysis.
- Takeaway: Shows a well-tuned baseline can be highly effective, even without novel contributions.