Stronger Baselines for Retrieval-Augmented Generationwith Long-Context Language Models
背景動機
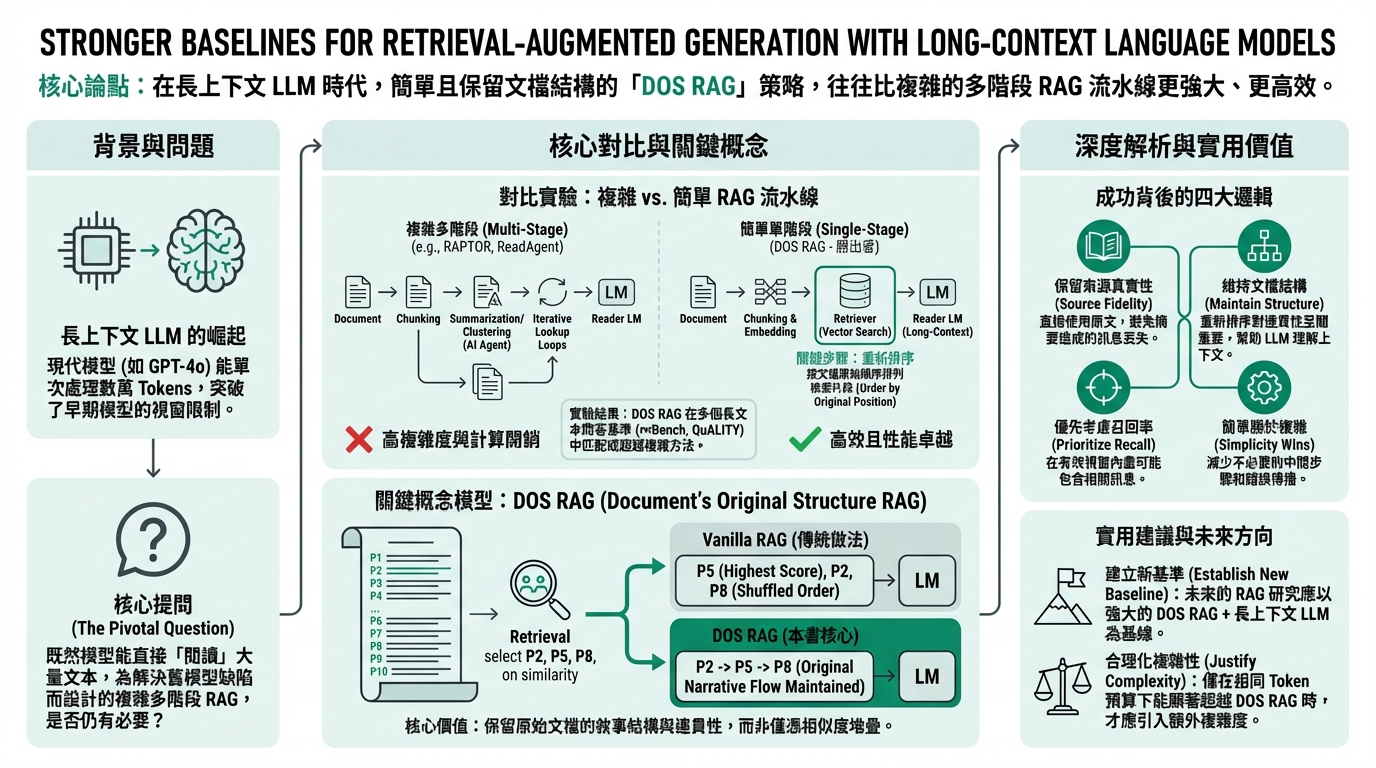
和過去相比,以前的模型可能只能看 2K ~ 4K token,而長文件一定需要:
切段、摘要、多次呼叫模型(多階段 RAG)
而卸載 Long-Context 語言模型的出現,可以一次處理數萬 Token,而開始思考
過去為了克服上下文限制而設計的複雜多階段 RAG 管線(如 RAPTOR、ReadAgent)是否仍有必要?
具體策略是 DOS RAG (Document’s Original Structure RAG):
- 仍然做 retrieval(不是整篇硬塞)
- 優先保留原文(不摘要),避免資訊損失
- 把取回的段落照原文件順序排列
- 在 LM 有效 context 範圍內(約 20K–30K)最大化 recall
在檢索後 保留原始文件的段落順序 再餵給語言模型,不是依相似度排序,而是依照段落在原文件中的順序排,更好的保守原文。