LONGAGENT - Scaling Language Models to 128k Context through Multi-Agent Collaboration
ACL 2020
Resource limitations when processing very long texts
再處理過長的文本時可能出現「中途迷失」(容易忽略中間資訊)
目的是將文本拓展到 128K,並在長處理超越其他模型
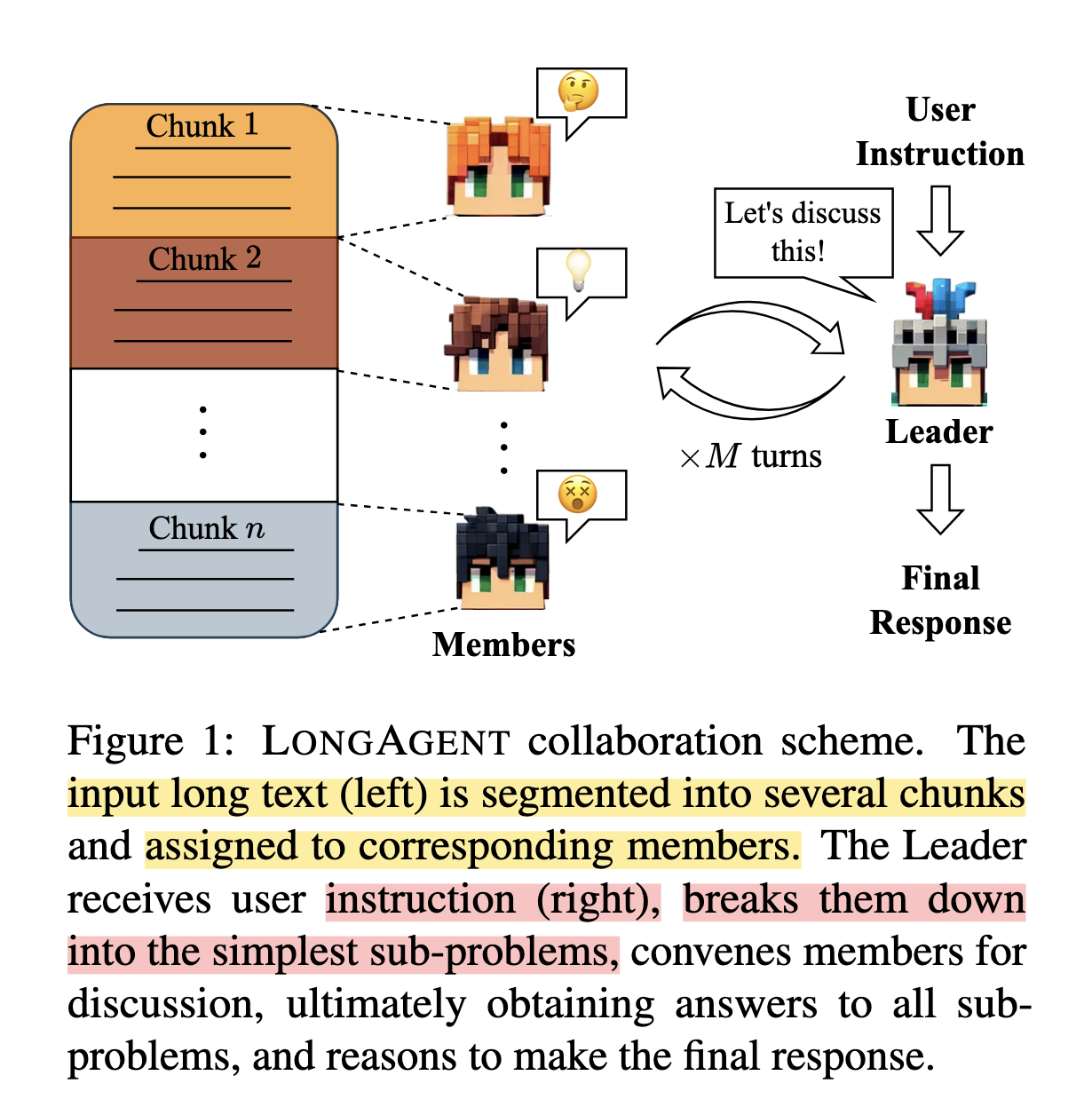
「Leader」
- 理解使用者問題
- 負責拆解問題為子任務
- 指派 「Members」 任務,指導 Members 從文檔中提取資訊
- 統整資訊做出最終回答
「Members」
- 處理各自的 Chunk
- 根據 Leader 指令做出回答
- 若產生衝突,會進行成員間溝通(互相分享 chunk 以消除 hallucination)
優點:
- 大幅降低計算資源需求(線性時間複雜度)
- 可處理超長文本(超越原始模型 context 限制)
- 多代理間溝通可有效降低 hallucination 發生率
Introduction
動機:
延伸 Positional Encoding 或 Sliding Window Attention, SWA 都有侷限
目的:
透過多代理協作機制,提升處理長文本的能
方法:
- 選擇成員模型(根據任務需求,選擇對應專家模型)
- 協作推理(Leader 拆問題,Members 分別查找資訊)
- Leader 根據過往對話狀態決定是要繼續詢問、解答、還是處理衝突
- 解決衝突(處理回答矛盾,避免 hallucination)
- 若成員回覆互相矛盾,
Leader 會讓這些成員「分享 chunk」後重新回答
- 若成員回覆互相矛盾,
- 推導最終答案
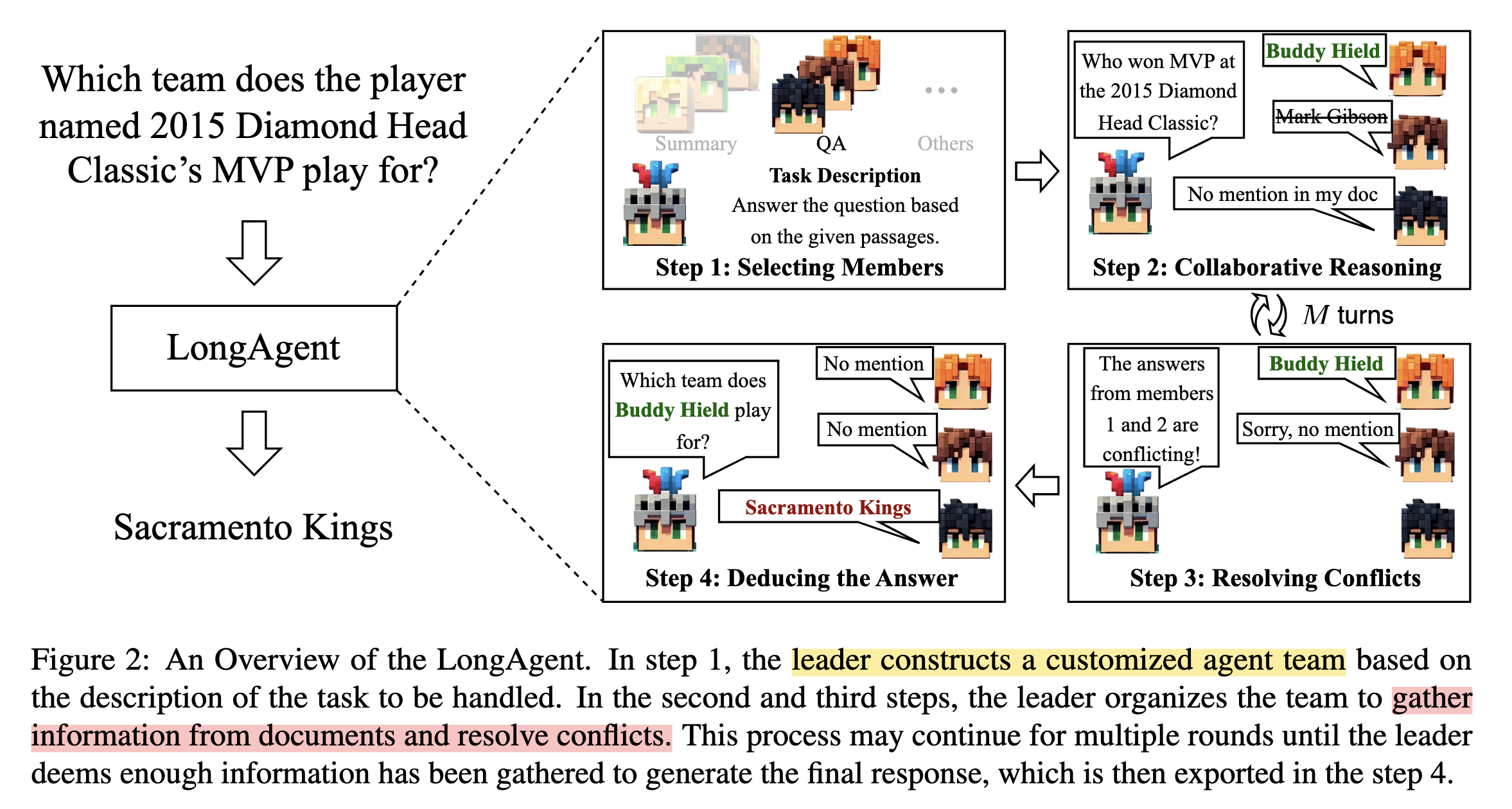
將文本
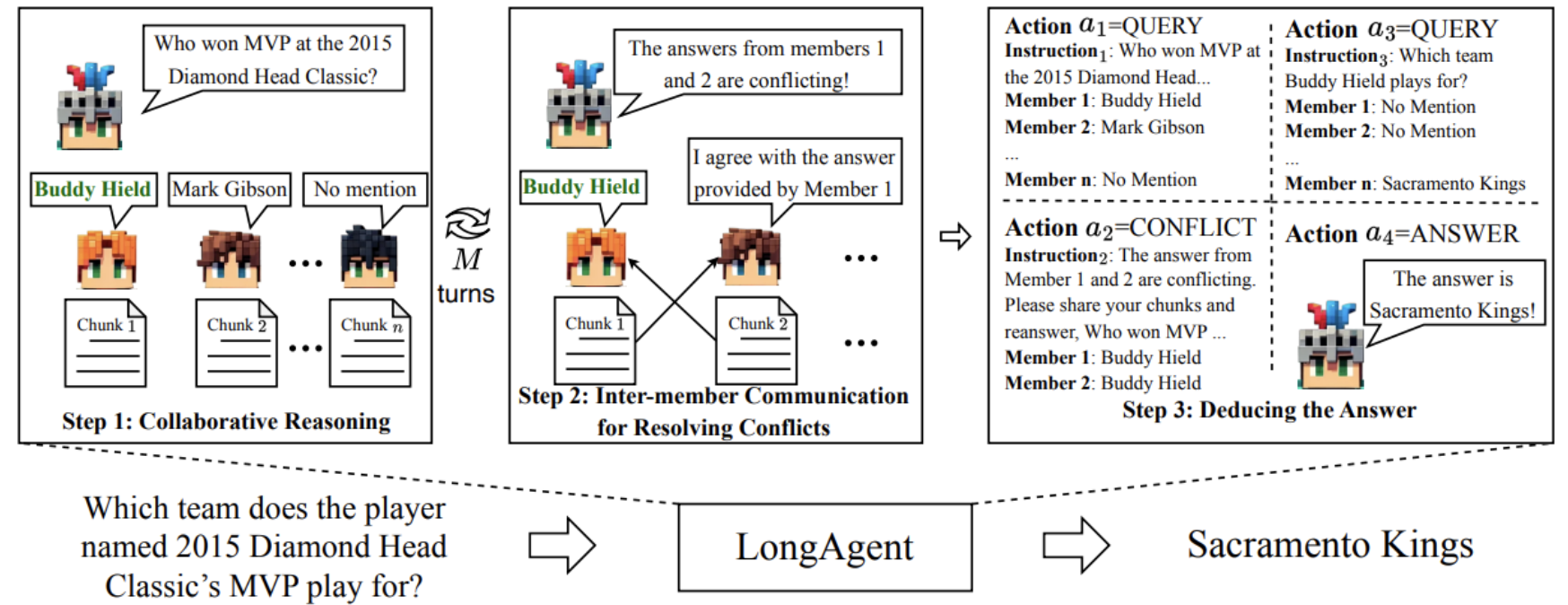
有趣的部分:
實驗: Hallucination Analysis
- 增加訓練時的「無答案」樣本(Reject)
- 為了證明沒有幻覺這件事情,輸入不可能有答案的 Fake Data.
- 增加 chunk 大小(但不能太大)