Adaptive Learning Rate (適應性學習率)
核心思想:
為每一個參數(甚至每個維度)動態分配不同的 Learning Rate (學習率),
而不是使用單一全域學習率。
期望行為
- 當梯度方向 陡峭(曲率大、梯度變化快)
- → Learning Rate 小 (↓) 以避免震盪或發散
- 當梯度方向 平坦(曲率小、梯度變化慢)
- → Learning Rate 大 (↑) 以加快收斂

為何需要?
Loss 停滯但梯度不小的情況
Training Stuck ≠ Small Gradient
此時模型既不是 Saddle Point(鞍點),也不是 Local Minima(局部最小點),只是 Loss 暫時無法下降。
在真正到達 Critical Point (臨界點) 前,可能會先出現 梯度過大 的情況。
例如,參數在損失地形的「懸崖」兩側來回震盪(如圖左),導致無法順利進入山谷區域。
理論上,若 Loss 長時間沒有下降,梯度應該接近 0,代表已停留在 Critical Point。然而,圖表紅色圈選的區域顯示:Loss 幾乎不變,但梯度仍劇烈波動,並未趨近 0。
這意味著模型並非真的落在 Critical Point,而是梯度方向在不同批次間急遽翻轉,使參數更新在某區域反覆擺動,形成 「表觀卡住」 的假象。

以下需要再整理
公式
1. Root Mean Square (RMS)
計算梯度的平方平均值,並以其平方根作為縮放因子,動態調整學習率。
本質是讓每一個梯度在計算中 同等重要,不分新舊。
做到這件事情,稍微修改一下式子:
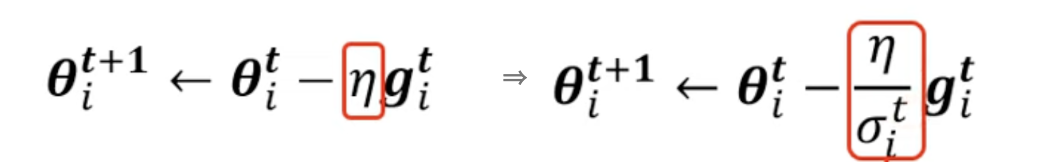
實作方法,將過去的所有gradien丟回去運算

上下圖片坡度不同,因此自動調整learning rate.

RMSProp

- Room Mean Square
- 每一個Gradient同等重要
- RMSProp
- 調整上面多了一個參數 𝛼,可以自由調整新舊gradient的比重(影響力),自行決定現在這個Gradient有多重要
- Adam
- RMSProp + Momentum
實現方式(常見演算法)
- AdaGrad:累積歷史梯度平方,對高梯度方向逐步減小 LR。
- RMSProp:使用梯度平方的滑動平均,避免 LR 持續衰減過小。
- Adam / AdamW:結合 RMSProp 的二階矩估計與 Momentum 的一階矩估計。
- Adafactor:記憶體更省,適合超大型模型。