Automatic Analysis of Substantiation in Scientific Peer Reviews
| type | url |
|---|---|
| Paper | 2311.11967 |
| Dataset | YanzhuGuo/SubstanReview |
| Conference | ACL2023 |
目的:Peer Review中的品質控制
提出以審查內容的證據支持性(substantiation)來評估評論質量
內容說明
隨著學術會議審查數量增加,審查品質不穩定問題凸顯,提出以審查內容的證據支持性(substantiation)來評估評論質量
- 同行審查的重要性:同行審查在學術出版過程中,評估論文質量與適用性方面扮演著關鍵角色(Price & Flach, 2017) #cite
- 問題陳述:近年來,同行審查的可靠性受到質疑,特別是在頂尖AI會議中(Tran et al., 2020)。這與提交論文數量暴增及領域專家短缺有關,導致評論質量下降(Publons, 2018;Russo, 2021;Ghosal et al., 2022) #cite
- 自動化評論生成:Yuan等人(2022)提出“正當性”作為自動評論生成模型的質量評估標準,認為高質量評論應提供具體理由 #cite
- 論證挖掘 (Argument Mining):Hua等人(2019)提出了AMPERE數據集,包含400篇帶有命題分段與分類(如評估、請求、事實等)標註的評論,並訓練神經模型進行任務處理 #cite
自動化質量控制的需求
- 目標:提供自動質量控制措施,以評估評論中的論點是否有足夠證據支持。
- 方法:定義為「論點-證據對」的抽取問題,並引入SubstanReview數據集,包含550篇由專家標註的NLP會議評論【SubstanReview】。
評論質量分析
- 質量評估方面:增長的投稿數給審查過程帶來挑戰,引發了大量研究(Severin et al., 2022)。其中,尤為重要的質量指標是“論據充分性”,即每個評論是否提供具體理由,特別是批評某方面不足時(Yuan et al., 2022)。
SubstanScore
目的:
- 論點-證據配對提取
- 透過模型自動抽取評論中的主觀性論點,並將其與相應的證據連結。
- 支持性評分
- 根據評論中支持性論據的比例和強度進行量化,以反映評論的合理性。
計算:
-
支持性百分比
- 計算評論中有證據支持的主觀陳述的比例,稱為
%supported_claims(這代表評論中的支持程度)
- 計算評論中有證據支持的主觀陳述的比例,稱為
-
評論長度加權
- 將
%supported_claims與評論長度(len(review),即字數)相乘 - 避免過短評論因支持性高而獲得過高評分,確保評論質量反映充分的實質內容
- 將
-
人類標註比對
- 透過與人類標註的質量評分比較,驗證 SubstanScore 與人類評估之間的相關性,確保其有效性
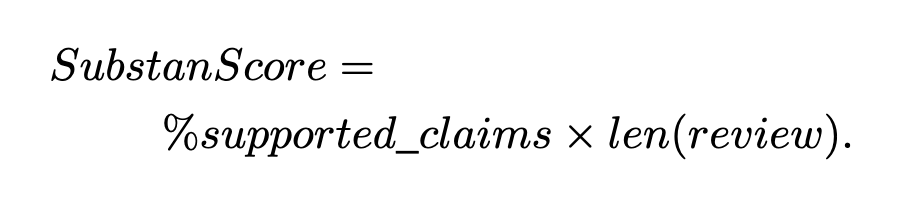
Dataset
研究者選用來自 NLP 領域的 NLPeer 資料集,因為它是目前最具倫理規範的同行評論語料庫。
作者選擇了 NLP 會議的評論(例如 CoNLL、ACL、COLING 等)進行標註,以避免其他 AI 子領域的評論風格差異對模型效能的影響。然而,這樣的選擇也帶來限制,因為資料僅涵蓋 NLP 範疇,限制了模型在其他 AI 子領域的通用性。
優缺點
優點:
- 填補實證性分析的研究空白
- 首個專門針對科學同行評審進行「主張-證據對」標註的數據集
- 多元化的評論標註
- 包含了正面評價(
Eval_pos)、負面評價(Eval_neg)、支持正面評價的證據(Jus_pos)、支持負面評價的證據(Jus_neg)以及主要主張(Major_claim)
- 包含了正面評價(
缺點:
- 資料來源、規模受限
- 目前的同行評審數據集普遍採用捐贈制的流程,即只有在 作者與審稿人雙方同意 公開的評審資料才會被納入
- 僅是 NLP 領域受限可能導致泛化不佳
- Bias (資料偏差)
- 只有自信評審質量較高的審稿人會願意公開其評審意見,因此數據集中的評論質量可能偏高。這導致數據集中的評審文本更傾向於高質量、有充分實證性的評審,而不代表現實中的所有評審質量分布。
- 真實場景中,評審質量往往更為參差不齊,因此基於該數據集訓練的系統在應用於實際場景時,可能會因為資料偏差而面臨挑戰
欄位說明
主張-證據對,目的是通過這種標註結構分析評論中的實證性水平,評估評論是否有足夠的證據支持其評價。
- Eval_pos:正面評價
- Jus_pos:正面評價的證據
- Eval_neg:負面評價
- Jus_neg:負面評價的證據
- Major_claim:主要主張
引用文獻
- Price, S., & Flach, P. A. (2017). Computational support for academic peer review: A perspective from artificial intelligence.
- Tran, D., Valtchanov, A., Ganapathy, K., et al. (2020). An open review of openreview: A critical analysis of the machine learning conference review process. arXiv preprint arXiv:2010.05137.
- Russo, A. (2021). Some ethical issues in the review process of machine learning conferences. arXiv preprint arXiv:2106.00810.
- Ghosal, T., Kumar, S., Bharti, P. K., & Ekbal, A. (2022). Peer review analyze: A novel benchmark resource for computational analysis of peer reviews. PLOS ONE, 17(1):e0259238.
- Severin, A., Strinzel, M., Egger, M., et al. (2022). Journal impact factor and peer review thoroughness and helpfulness: A supervised machine learning study. arXiv preprint arXiv:2207.09821.
- Yuan, W., Liu, P., & Neubig, G. (2022). Can we automate scientific reviewing? Journal of Artificial Intelligence Research, 75:171–212.
- Hua, X., Nikolov, M., Badugu, N., & Wang, L. (2019). Argument mining for understanding peer reviews. ACL HLT, 2131–2137.
速讀, Support by GPT-4o.