Agent-FLAN, Designing Data and Methods of Effective Agent Tuning for Large Language Models
訓練資料
訓練語料同時包含格式遵循與推理,偏離原始預訓練語域(自然對話)
為什麼格式資料會導致「學習不足」?
太格式化的資料會讓模型「只學會形式,不學會推理」
⇒ 導致 Agent 表現差
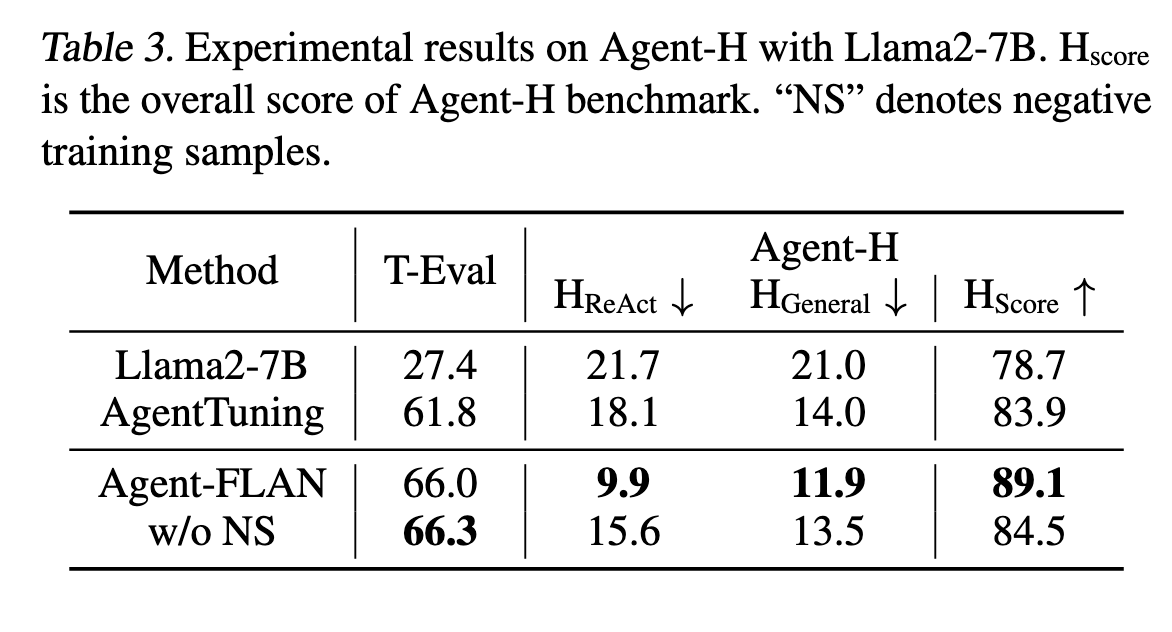
ReAct
- 格式 loss 很快下降(容易擬合格式)
- 內容 loss 仍高(模型沒真正學會推理)
而自然對話資料學得慢,但內容學得比較紮實
對齊預訓練語域(Aligning Agent Tuning to Chat Domain)
現有 Agent 訓練語料使用 ReAct / JSON 等格式,但是與 LLM 預訓練的「自然語言對話」語域不一致,這導致模型過度擬合格式,忽略了推理與理解能力的學習。
⇒ Thought-Action-ActionInput 格式 → 「多輪自然對話」形式
模型與任務的學習速度
模型學習能力?
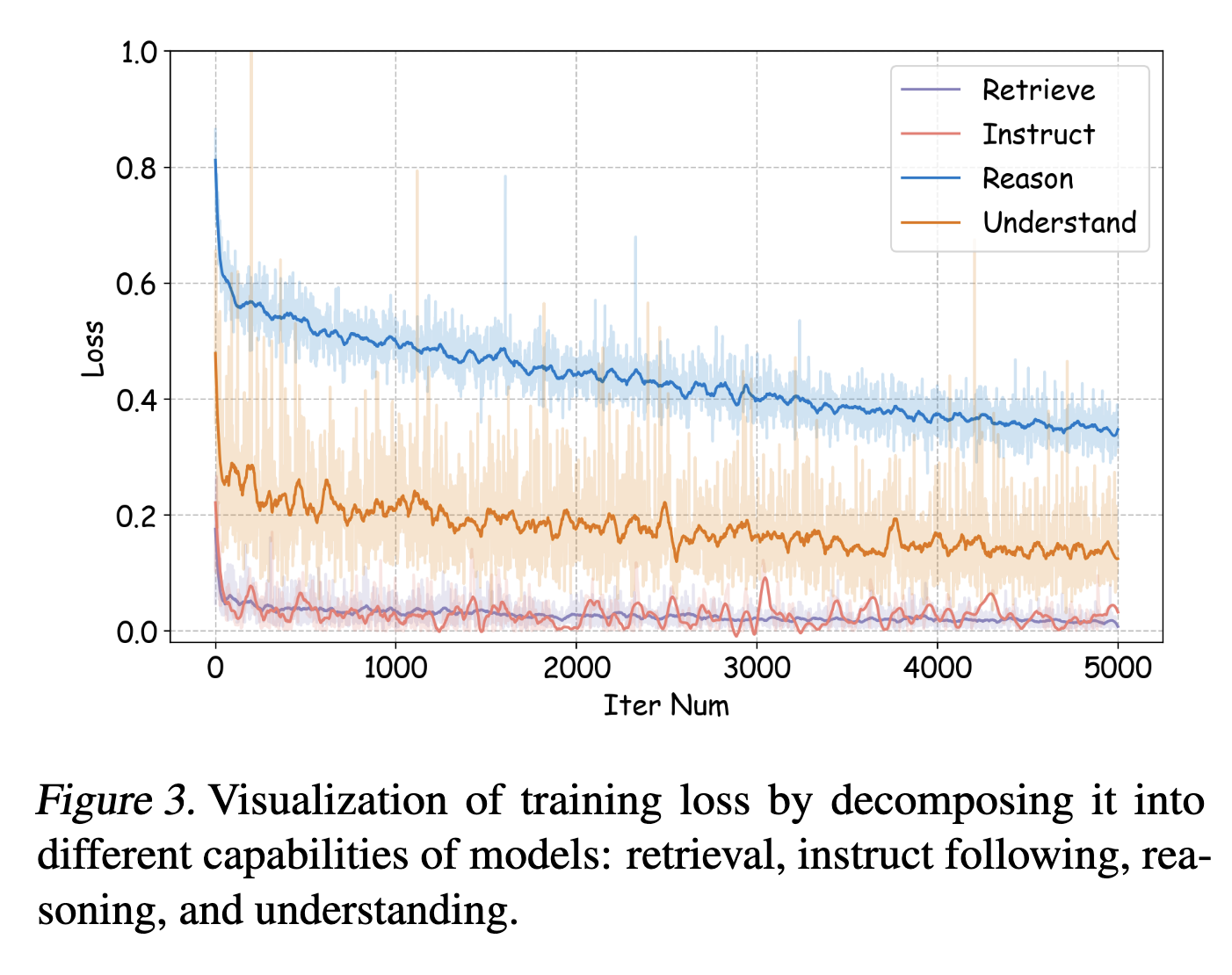
模型對不同任務能力有不同的學習速度,訓練時要依能力調整資料比例:Instruction Following 收斂最快,Reasoning 收斂最慢(最難學)
模型能力被拆成 4 類:
- Instruction Following(格式遵循)
- Retrieval(工具選擇)
- Understanding(參數理解)
- Reasoning(推理能力)
Capabilities Decomposition and Data Balancing(能力拆解與資料平衡)
不同 agent 任務涉及不同基本能力(如檢索、推理、理解),模型對這些能力的學習速度不同,若不調整資料比例,會導致訓練偏向學得快但不重要的能力。
- 移除部分推理資料 → 性能明顯下降。
- 移除檢索或格式資料 → 幾乎無影響,有時甚至提升。
幻覺
Agent 為什麼會造成幻覺?
當前 agent 訓練方式容易導致模型「過度主動」,不分青紅皂白就產生格式或行動,這會在真實應用中造成錯誤和安全風險
目前 Open-Source LLM 在 agent 任務中,常見的 Hallucination(產生錯誤或不合時宜的輸出) 問題:
- 格式幻覺:使用者問一個普通問題,但模型卻硬要用 ReAct 格式回答
- 行動幻覺:使用者請求使用工具,但模型產生一個不存在的工具或函數

Negative Sample Learning for Hallucination Elimination(引入負樣本學習以消除幻覺)
- 建立 Agent-H benchmark,專門評估 hallucination 現象(格式與行動層級)
- 加入負樣本訓練:設計兩類樣本來教模型「什麼時候不要當 agent」
- 使用者請求工具,但系統未提供工具
- 提供工具,但使用者只想對話
HScore 反映模型在不該使用工具時的自制能力(幻覺控制能力)
引入負樣本後,Agent-FLAN 在 Agent-H 指標上 hallucination 顯著降低(如 HReAct 從 15.6% 降至 9.9%)。