L1 vs L2 正則化 — 實務差異
當模型太「聰明」時,容易記住訓練資料的細節而失去泛化能力
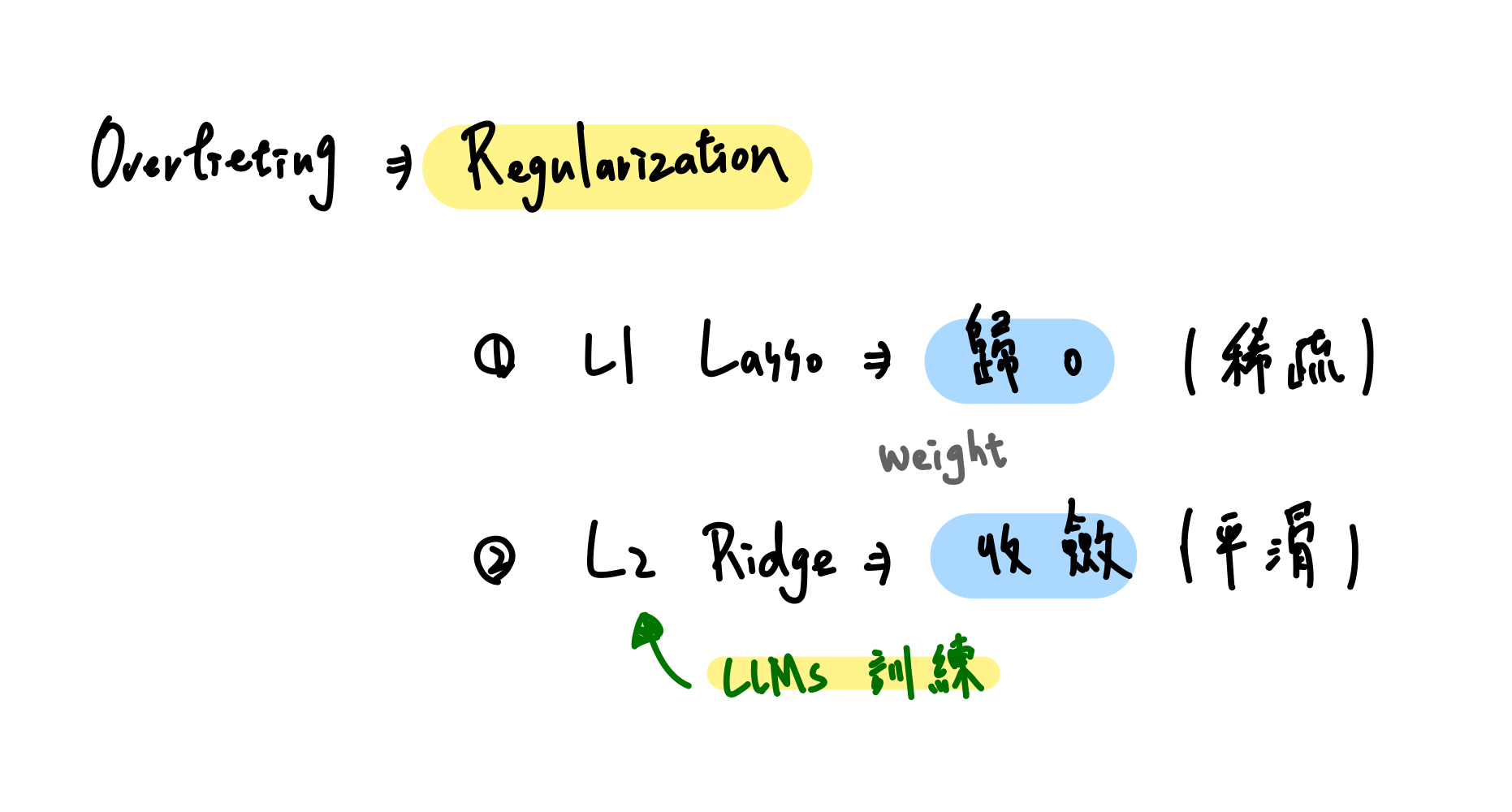
⇒ 這就叫 overfitting(過擬合)
為了讓模型更穩定,我們會對權重加上一點「懲罰」
這個懲罰就是 Regularization (正則化)
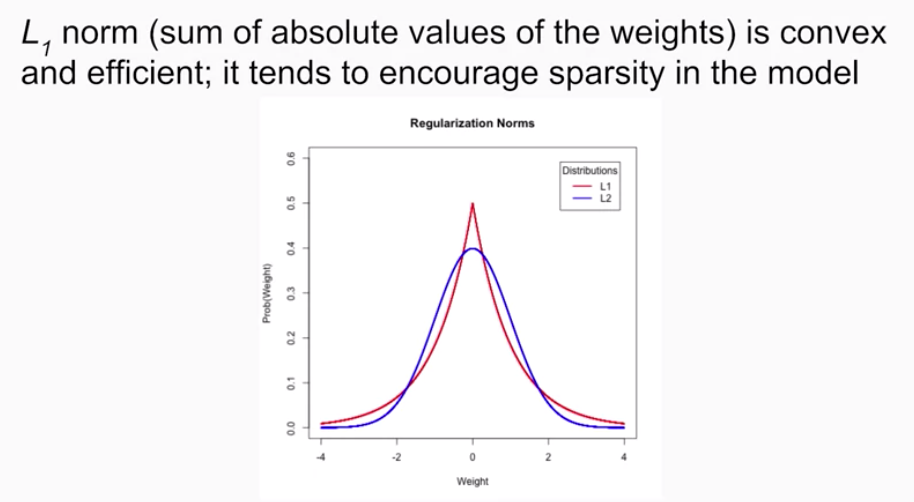
- L1 Regularization(Lasso) 讓權重能「乾脆歸零」
- 斷捨離 ⇒ 不重要的東西直接丟掉(權重變 0)
- L2 Regularization(Ridge) 讓權重「收斂但不消失」
- 節省空間 ⇒ 權重變小但保留
| 方法 | 概念 |
|---|---|
| L1 (Lasso) | 懲罰 權重絕對值 |
| L2 (Ridge) | 懲罰 權重平方 |
實務情境選擇
| 情境 | 建議使用 | 為什麼這樣用 |
|---|---|---|
| 特徵超多又稀疏(像是 NLP 的 bag-of-words、One-hot) | L1 | 直接把不重要的特徵壓成 0,讓模型更精簡。 |
| 特徵彼此高度相關(像多重共線性) | L2 | 把所有權重平均壓小,模型會更穩定不亂晃。 |
| 樣本少但特徵多(例如醫療資料、高維資料) | L1 或 Elastic Net | 可以選出真正有影響力的變數,同時避免過擬合。 |
模型穩定性與泛化能力
- L1:比較「狠」,會把一些權重直接砍掉;
好處是模型簡潔、可解釋,但壞處是對資料微小變動比較敏感。 - L2:比較「溫和」,只是讓權重都小一點;
通常能讓模型更平滑、更能適應新資料。
⇒ 在深度學習或連續預測任務裡,幾乎都用 L2(weight decay)
訓練與收斂特性
- L1 的懲罰在 0 附近不連續 → 梯度跳躍,訓練可能比較抖動。
- L2 的懲罰平滑 → 與 Adam / SGD 這類優化器更相容,訓練穩定。
⇒ 因此在 GPU 上訓練大模型,L2 幾乎是標配
主流 LLM 微調(如 LLaMA、GPT、Mistral、Gemma 等)主要使用 L2 正則化