RepoAgent - An LLM-Powered Open-Source Framework for Repository-level Code Documentation Generation
針對專案進行自動生成文檔,並且可以自動更新,因此不用工程師手動維護,且可以讓新成員透過專案快速理解。
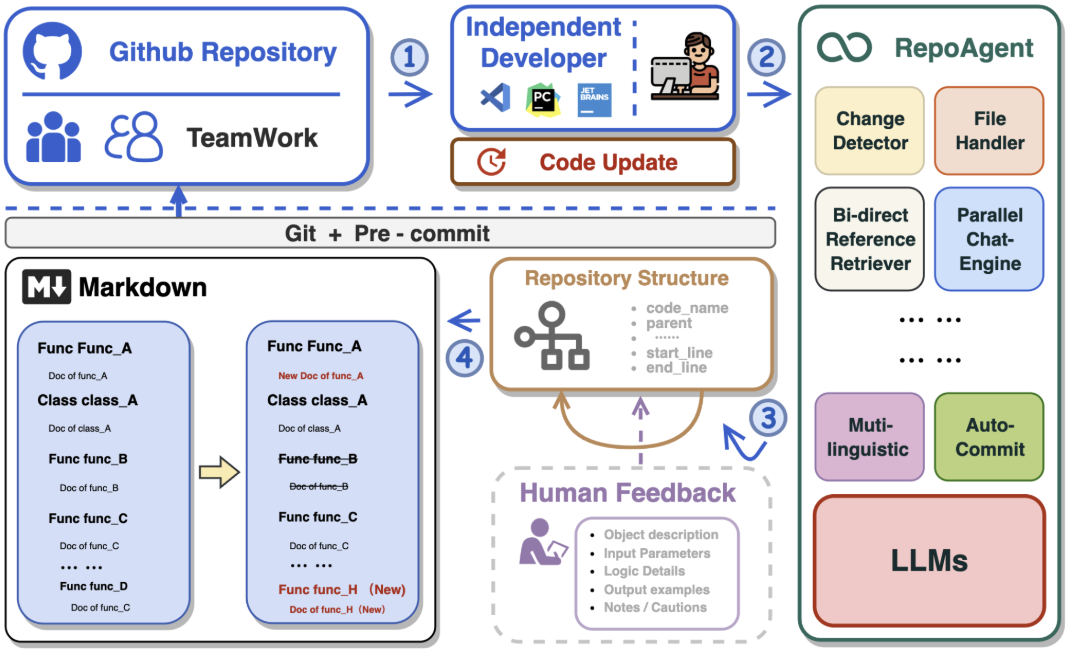
Framework
- 開發者對 Github Repository 進行 Code Update
- RepoAgent 的自動處理
Change Detector:偵測哪些程式碼有變動File Handler:讀取相關檔案Bi-directional Reference Retriever:比對「函式誰呼叫誰」Parallel Chat Engine:多執行緒處理生成流程- 其他模組:如多語系處理(Multi-linguistic)、自動提交(Auto-Commit)等
- 分析結構與人類回饋
- 建立/更新 Repository Structure,包含
code_name,parent,start_line, `end_line - 結合可能的 Human Feedback (option),補充功能、參數、邏輯、範例與注意事項
- 建立/更新 Repository Structure,包含
- 自動產生/更新文件(Markdown)
- 根據變動與結構關係,產生/更新對應的文件區塊 → Markdown
- 修改函式會更新說明(紅字)
- 新增函式會自動加入(標記為
New) - 舊的未變更項目會保留原樣
- 根據變動與結構關係,產生/更新對應的文件區塊 → Markdown
- 成果同步回 GitHub
📌 問題背景
過去的文檔摘要
開發者花了約 58% 的時間在理解程式碼,高品質文件能有效減少這些負擔
但維護文件本身也很花時間、人力與資源
早期自動文件生成的嘗試
雖然為了減輕人工維護負擔,早期研究曾嘗試 自動產生程式碼摘要,
但這些方法仍存在明顯限制:
- Poor summarization quality(品質不佳) :僅針對片段程式碼,忽略專案整體結構與依賴關係。
- Lack of usage guidance(缺乏引導性):沒有參數說明、範例或誤用提示,難以實際幫助開發者使用。
- No auto updates(無法自動同步更新):當程式碼變更時,文件無法及時更新,導致資訊過時。
⇒ 這些限制讓自動文件生成雖具潛力,但在實務上仍難真正落地。
🤔 問題核心
LLMs 現在在程式理解與生成已大幅進步,那麼:
是否能用 LLM 來自動產生並維護 repository 級別的程式碼文件,解決上述問題?
Can LLMs be used to generate and maintain repository-level code documentation, addressing the aforementioned limitations?
目標:
- Repository-level documentation:能理解整個專案的脈絡,產生正確、有意義的結構化說明
- Practical guidance:不只說明功能,還提供使用建議和輸入輸出範例,幫助開發者快速理解
- Maintenance automation:與 Git 整合,主動維護和同步更新
🍎 REPOAGENT
一個開源工具,用 LLM(大語言模型)自動產生與更新整個專案的程式碼文件
自動理解全專案結構,並產生高品質、有引導性的說明文件。
🏗️ 核心流程
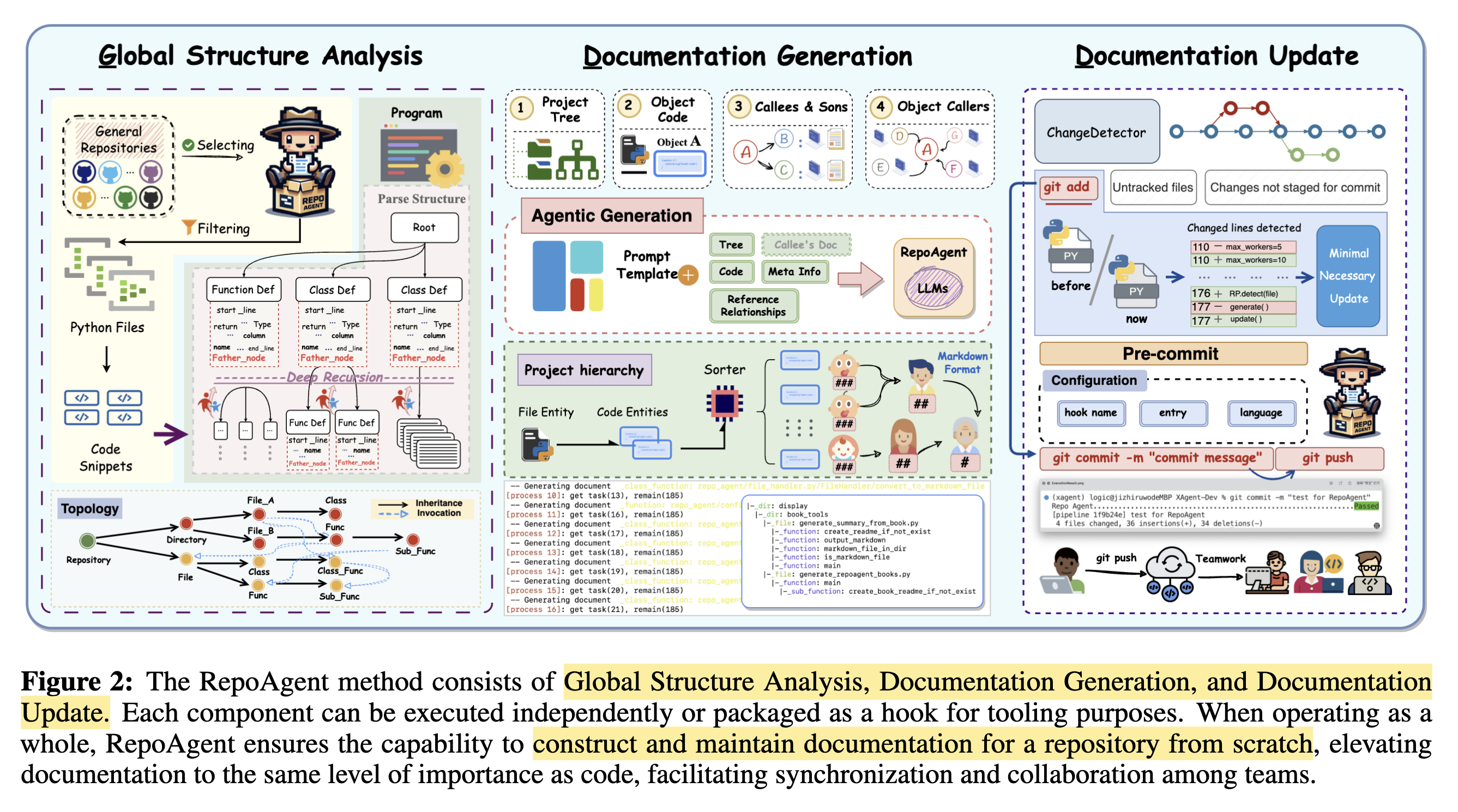
全域結構分析(Global Structure Analysis)
為了產生語意完整且結構清晰的文件,REPOAGENT 首先對整個程式庫進行全域結構分析:
-
過濾與 AST 解析
- 篩選出
.py的 Python 檔案 - 對每個檔案進行 AST(Abstract Syntax Tree) 解析:
- 遞迴解析出所有 Class 與 Function
- 抽取:
name,type,code snippet等基本資訊 - 每個 Class/Function 都視為一個獨立的「程式碼物件」
- 篩選出
-
建立 Project Tree
- 建立一棵描述整個專案結構的 Project Tree:
Root= Repository中間節點= 資料夾與 Python 檔案Leaf= AST 解析出的 Class / Function(成為後續文件生成的基本單位)
- 建立一棵描述整個專案結構的 Project Tree:
-
擷取全域引用關係(Global Reference Relationships)
- 使用 Jedi Library 抽取雙向呼叫關係:
- Caller:誰呼叫了該函式/類別
- Callee:該函式/類別又呼叫了誰
- 將這些關係綁定回 Project Tree 節點,加入結構語意
- 使用 Jedi Library 抽取雙向呼叫關係:
-
轉換為有向無環圖(DAG)
- 結合 Project Tree 的階層結構與引用關係,形成一棵
DAG(Directed Acyclic Graph)- 為 LLM 提供更完整的 語意上下文(global context)
- 可依照 拓撲順序(Topological Order) 產生文件,確保依賴順序正確
- 結合 Project Tree 的階層結構與引用關係,形成一棵
- 有向(Directed):每條邊都有方向(A → B 表示 A 依賴 B)。
- 無環(Acyclic):不會有循環(例如 A → B → C → A 這種情況不允許)。
文件生成(Documentation Generation)
根據 Global Structure Analysis 的結構分析結果
輸出的格式是 Markdown → 由 Gitbook 轉換為網頁畫面,文件格式內容為:
- Functionality:功能說明
- Parameters:參數名稱與說明
- Code Description:程式碼細節說明與邏輯
- Notes:使用注意事項
- Examples:使用範例與回傳值展示(視情況有無)
⇒ 生成時的 Prompt 中會包含以下資訊
(C.1 A full prompt of ask_user method in AutoGPT)
- Project Tree
- 表達物件層級,擁有全域上下文
- Code Snippet
- 該 Class 或 Function 的實際程式碼,是文件生成的主要依據
- Reference Relationships
- Caller 與 Callee,用於輔助推論語意與生成範例/使用指引
- Meta Info
- 文件標示與 post-processing
- Child Documentation
- 子節點文件可作為輔助說明,幫助理解
- 大括號 {} 內為變數欄位
- 藍色文字 部分為關鍵補充, 根據物件 Meta Infor 自動生成
- 虛線框 (Dashed Boxes) 為可選資訊
以上資訊存在引用依賴,若缺少則無法依拓樸順序 (Topological Order) 正確生成文件

⇒ 文件產出順序:Bottom-to-Top 拓撲順序
- 為了確保依賴順序,從 DAG 底層開始產生文件
- 若無則可能會導致無法正確描述引用關係
⇒ 輸出格式 Markdown
- 自動轉換為分層標題(如
##,###)的 Markdown 文件 - 支援 GitBook 渲染,最終呈現為可導覽的 Web 文件,方便閱讀與理解
將 Markdown 文件轉換成漂亮網頁格式的工具與平台
⇒ GitBook = 文件 + Markdown + Web 頁面
文件更新(Documentation Update)
方法:利用 Git 的 pre-commit hook
→ 每次程式碼提交前,自動檢查是否有需要更新的文件,實現程式碼與文件的即時同步
觸發更新的條件:
僅在特定條件下更新,避免重複計算與資源浪費
- 該物件本身的程式碼被修改(例如新增邏輯、修改參數等)
- 原本有「呼叫它」的函式不再呼叫它(失去引用)
- 有新的函式開始呼叫它(新增引用)
❌ 不會觸發的情況
若只是該物件所呼叫的其他函式(callee)發生變更,則不會觸發更新
→ 根據依賴反轉原則(Dependency Inversion Principle),高層模組不應依賴低層模組的實作細節,因此不更新(簡單來說只考慮是否呼叫或被呼叫,不考慮呼叫實作邏輯)
✅ 優點總結:
- 保持程式碼與文件同步
- 只更新必要的區塊,高效省資源
- 全自動處理,不需開發者介入
高層模組(例如:業務邏輯)不應該依賴低層模組(例如:細節實作);
兩者都應該依賴於抽象(interface or abstraction)
🧪 實驗設計與結果
📂 資料來源
- 從 GitHub 選 9 個 Python 專案,範圍從 1k 到 10k 行程式碼。
🔧 模型選用
- 商用 LLM:
gpt-3.5-turbo、gpt-4-0125 - 開源 LLM:
Llama-2-7b、Llama-2-70b
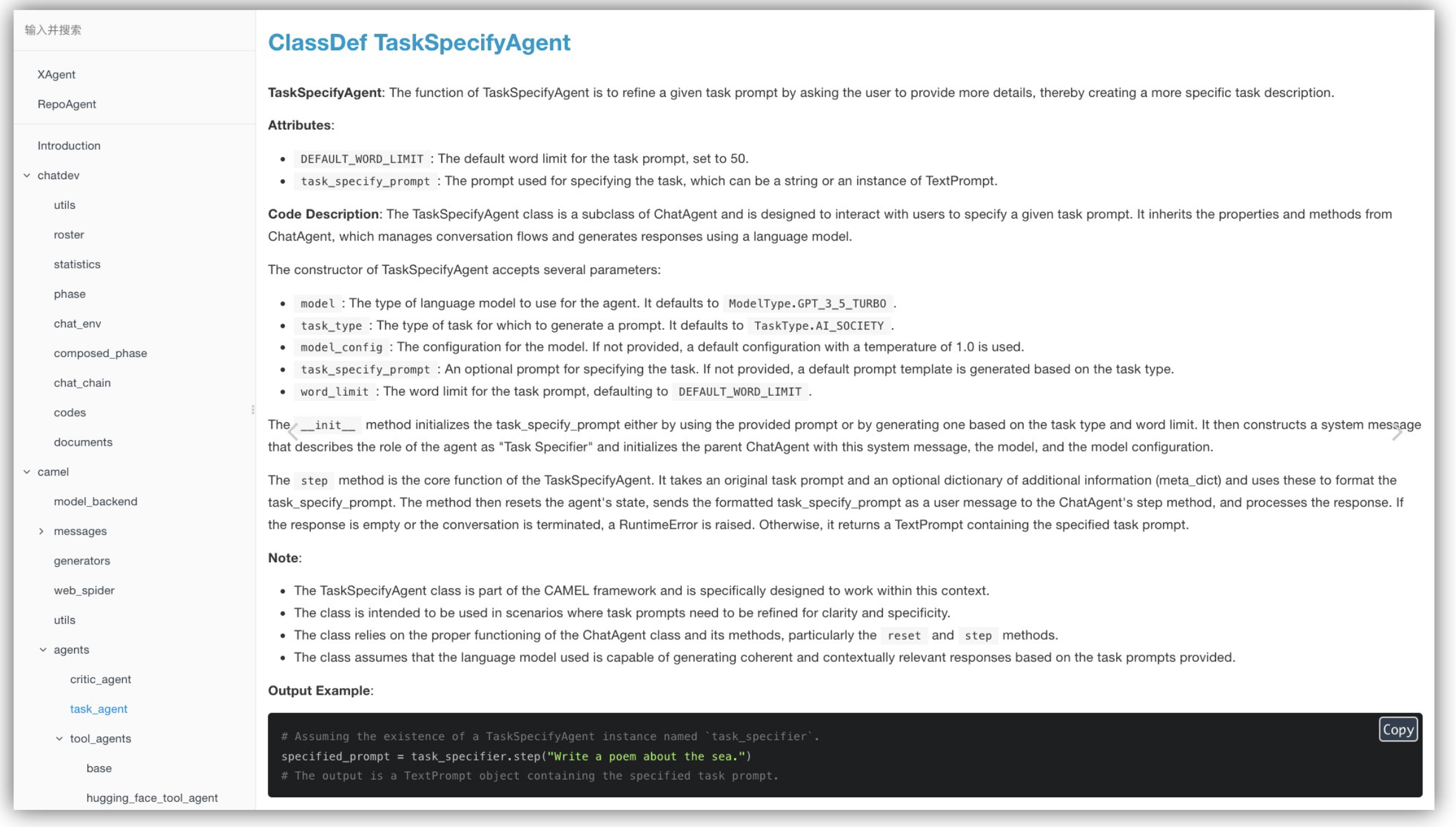
🔍 Case Study(ChatDev 專案)
- 使用 GPT-4 與 ChatDev 專案實測。
- 自動產生、更新文件,整合至 Git,無需手動操作。
當 程式碼變更(staged)時:
- REPOAGENT 會偵測到受影響的物件及其 雙向引用。
- 僅更新受影響範圍的文件。
- 自動產生新的 Markdown 文件(含新增或移除的內容)
整合至 Git 的 pre-commit hook,無需額外操作,更新後會顯示 "Passed",保持開發者原有工作流程不變
🧑⚖️ Human Evaluation(人工評估)
由於目前尚無可靠的自動化方法能準確評估「程式碼文件的細緻程度與實用性」, 因此採用**人工偏好測試(Preference Test)**來進行評估。
📊 評估流程
- 比較對象:REPOAGENT 生成的文件 vs. 人類撰寫的文件
- 評估資料:
- 從兩個知名開源專案(Transformers、LlamaIndex)中隨機抽取
- 共 150 個文件項目(100 個 class + 50 個 function)
- 評估人員:3 位獨立評估者
- 評估準則:文件清晰度、完整性、實用性
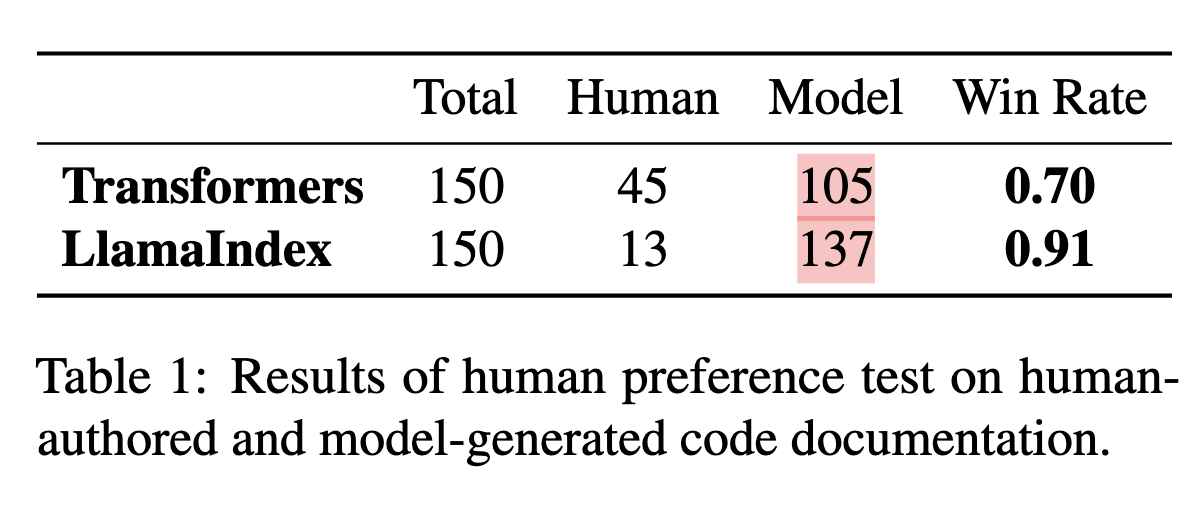
REPOAGENT 在兩組資料中均被評為 優於人類撰寫的文件,展現其高度實用性與文件品質。
📊 量化分析
- Reference Recall
- 模型辨識全域函式引用關係的能力
- → 看模型能不能找出「誰呼叫誰」的函式關係
- Format Alignment
- 模型生成文件是否符合格式要求
- → 看模型產生的文件格式有沒有對
- Parameter Identification
- 模型是否能準確辨識參數資訊
- → 看模型能不能正確列出每個函式的參數
(不會亂加沒出現過的(幻想)參數。)
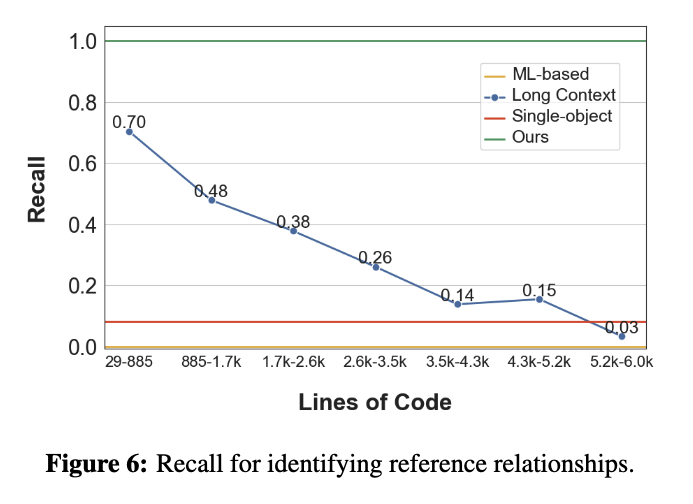
Reference Recall(函式引用關係召回率)
評估模型是否能辨識程式碼中的全域呼叫關係(Caller & Callee)
- ML-based(LSTM)
- 傳統註解生成方式
- ❌ 幾乎無法識別引用關係(召回率為 0)
- Single-object
- 只給模型單一函式程式碼
- ⚠️ 只能部分識別 Callee,無法識別 Caller (Recall keep 0.1)
- Long Context
- 使用長上下文模型(如 128k tokens)讀整包程式碼
- ⚠️ 效果有限,隨上下文變長召回率下降
- RepoAgent
- 使用靜態分析工具(Jedi)與 Project Tree 進行雙向綁定
- 👍 穩定準確識別 Caller/Callee,克服記憶推理的限制 (Recall 1.0)
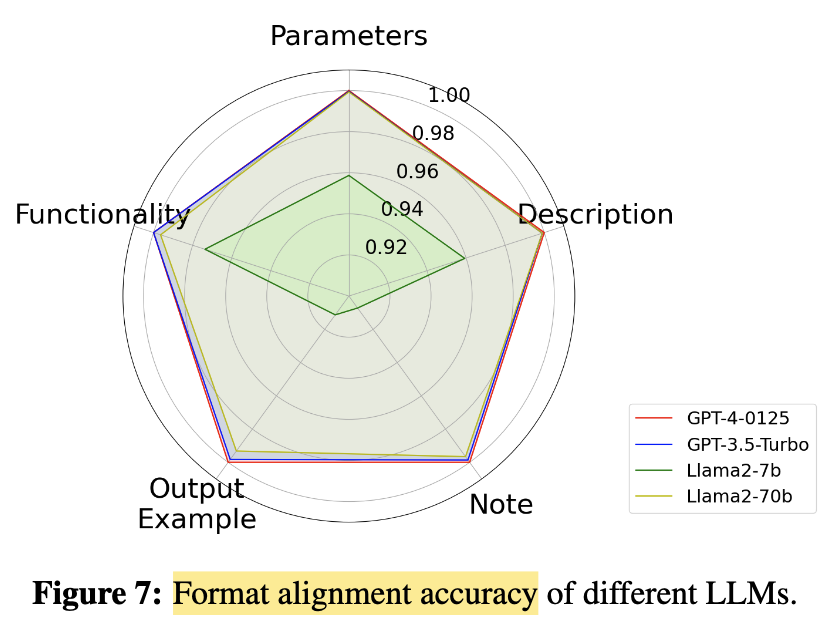
Format Alignment(文件格式對齊)
文件應遵循固定格式,共 5 個區塊:
- Functionality
- Parameters
- Code Description
- Notes
- Examples(🔁 有 return 值才需要)
結果:
- GPT 系列(gpt-3.5 / gpt-4):表現穩定,格式完整
- LLaMA-2-70b:表現也不錯
- ❌ LLaMA-2-7b:常漏掉格式,特別是 Examples 區塊
⇒ 大模型比較能遵守格式,小模型容易漏關鍵內容。
格式不只是排版問題,更是文件可用性與可維護性的基礎
- 提高可讀性
統一的格式讓開發者能快速掃描與理解每段文件,不會漏看重點 - 促進開發協作與維護
格式一致的文件讓團隊更容易維護,避免資訊混亂或遺漏。 - 方便自動處理與工具整合
機器或工具(如 GitBook、IDE 插件)可根據結構解析內容,提供更好的輔助功能。
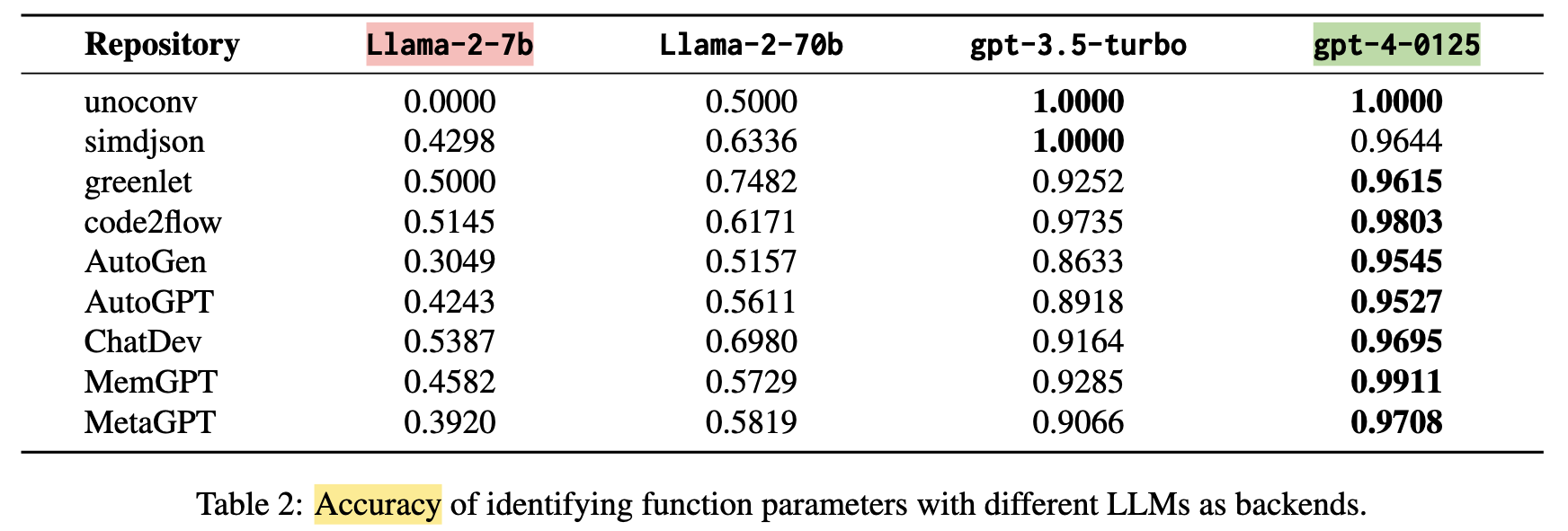
Parameter Identification(參數識別)
評估模型是否能正確辨識函式的參數名稱與說明
有些模型會產生「幻想出來的參數」(Hallucination)
例如:文件裡寫了 data_type,但實際程式碼根本沒有這個參數
⇒ 使用 準確率(Accuracy) 能反映有多少是「真的存在」且「沒有多寫」的參數
- GPT 系列(特別是 GPT-4-0125) → 表現最佳,參數識別準確
- LLaMA 系列:
- LLaMA-2-70b → 普通
- ❌ LLaMA-2-7b → 最差,常誤加不存在的參數
⇒ 模型越大,參數識別越準確。GPT 系列在避免幻想參數上有明顯優勢。
✏️ Conclusion & 未來展望
貢獻
- 提出 REPOAGENT:
一套開源框架,可自動產生 細緻的 repository-level 文件 - 除了「主動生成」,還能在程式碼改動時「自動維護」
未來展望:
- 實際部署應用:探索如何在開發流程中更有效整合 REPOAGENT
- 延伸任務整合:將其應用於更多下游任務(如測試生成、程式理解輔助)
- Chat With Repo(概念初步實現中):
- 結合 RAG(Retrieval-Augmented Generation)
- 融合程式碼、文件與引用關係
- 嘗試建立一種 「與程式對話」的新型開發模式
⇒ REPOAGENT 標誌著程式碼文件自動化的新階段,未來有望推進「可互動式開發」的新典範。
🔍 相關工作
Code Summarization 發展歷程
規則式 → LSTM → Transformer(注意力機制處理長距離依賴)
- Early:規則式或樣板式技術(rule-based/template-driven
- ML-base: CODENN(Iyer et al., 2016) 的方法,使用 LSTM(長短期記憶) 建立模型來學習產生摘要。
- Transformer: 引入 Attention 機制 和 Transformer 架構(例如 Vaswani et al., 2017),處理更長距離的依賴關係,提升上下文理解能力
主要是從固定樣板 → 生成摘要 → 提升上下文長度與敏感性
LLM 發展階段
- Masked Language Modeling(遮蔽預測): BERT
- 主要用於理解任務(如分類、問答
- Encoder-Decoder: T5 series
- 適合各種生成任務(例如翻譯、摘要)
- auto-regressive: GPT series
- 序列生成,特別適合程式碼生成、文件生成等連續內容的任務
結論
REPOAGENT:
- 自動理解與產生專案層級程式碼文件
- 能主動更新、提供正確依賴資訊與使用範例
- 降低維護負擔,提升開發效率與團隊合作
| 傳統方法 | REPOAGENT |
|---|---|
| 單段程式碼處理 | 解析整個專案全域結構(AST + DAG) |
| 忽略函式關係 | 雙向追蹤 Caller / Callee |
| 文件品質低 | 多段落格式,涵蓋參數、範例、備註等 |
| 被動更新 | 與 Git 整合,主動追蹤並更新文檔 |
延伸應用與未來展望(Future Work)
開啟新型態開發流程:「Chat With Repo」= 用 LLM 對話式理解整個專案
Chat With Repo 概念
- 利用 RAG(Retrieval-Augmented Generation) 技術,
- 結合:
程式碼+文件+函式間引用關係
- 結合:
- 打造「可對話的程式碼庫」,讓開發者:
- 問:「這個函式是做什麼的?」
- 問:「它在哪裡被呼叫?有沒有範例?」
- 開啟 自然語言與程式碼互動的新模式(Coding Paradigm)
小結總覽
✅ REPOAGENT 解決了程式碼文件三大痛點:
- 品質不佳 → 理解全域依賴,提升內容深度
- 缺乏指引 → 結構化產出包含使用建議與錯誤警示
- 難以維護 → 整合 Git,自動更新
🔧 適用場景:
- 開源專案維護者
- 軟體團隊協作
- 教學與單元測試輔助
🧭 未來方向:
- 結合 Agent 技術實現更多自動開發任務
- 更智慧的「Chat with Repo」互動體驗