LongLLMLingua - Accelerating and Enhancing LLMs in Long Context Scenarios via Prompt Compression
簡介與動機
LLMLingua 是透過小型的語言模型 (e.g. GPT2-small) 來壓縮 Prompt 的技術,透過刪除不重要的 token,減少成本與延遲,甚至可達 20 倍壓縮率
LongLLMLingua
⇒ 進一步針對 長上下文情境(Long Context) 解決:
- 成本與延遲上升
- Porompt 越長,輸入 Token 越多,成本上升
- 長序列會增加 LLM 的計算複雜度造成延遲變長
(e.g Transformer 為 O(n²)) - ⇒ 在實際應用中(如聊天機器人),快速與低成本是關鍵需求,直接影響可落地性與用戶體驗
- 模型性能下降
- 長 Prompt 若有雜訊與冗詞,稀釋關鍵資訊密度
- 若 處理雜訊能力仍有限,會導致預測不準
- ⇒ 提高資訊密度才是真正有效的提示設計
- 資訊位置偏差(例如關鍵資訊被夾在中間失效,"Lost in the Middle" 問題)
- 開頭與結尾的資訊較敏感,中間區段常被忽略
- 類似還有 LONGAGENT - Scaling Language Models to 128k Context through Multi-Agent Collaboration
- ⇒ 若模型無法穩定掌握中間內容,將嚴重限制其效能與可靠性
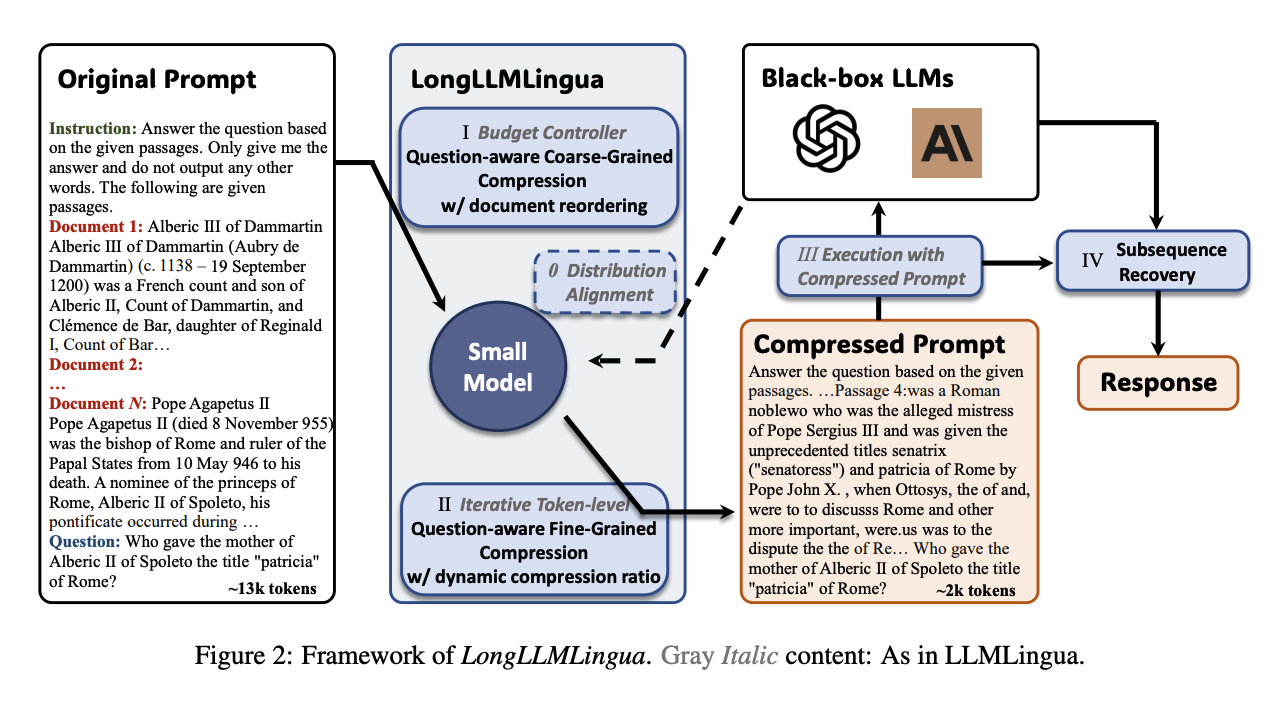
核心技術概念
1. 兩層壓縮架構(Coarse-to-Fine)
-
第一層:粗粒度壓縮
- 利用小模型根據 Question 計算每份文件的重要性
,指保留重要文件 - 利用小模型根據問題(Question)來計算每份文件的重要性(
r_k),只保留重要文件。 - 用來衡量第
個文件的重要性,數值越大代表越關鍵 - 若我有這份文件,是否能產生這個問題?
= 衡量該文件是否包含解釋問題的資訊
- 用來衡量第
- 利用小模型根據 Question 計算每份文件的重要性
-
第二層:細粒度壓縮
- 對保留的文件進行逐字(token-level)壓縮
- 引入 對比困惑度(Contrastive Perplexity):
- 能更準確評估 token 是否與問題有關
限制語句(Restriction Sentence)
額外附加在問題(Question)後的一小段話,目的是限制模型回答的範圍,因為 LLMs 計算困惑度時,可能會預設猜測常見問法,而模型可能會使用本身知識回答,這會讓模型產生幻覺、或回答資訊不可靠等問題
- 讓模型專注於文件與問題的關聯性
- 減少 LLMs 本身的干擾
2. 文件重排序(Document Reordering)
- 長 prompt 中資訊放在開頭比較有效,若關鍵資訊在中間容易被忽略
- 依據
的重要性排序文件,將最相關的放在最前面
3. 動態壓縮比例(Dynamic Compression Ratio)
- 每份文件的重要性不同,不應套用相同壓縮比例。
- 根據
對不同文件分配不同壓縮 budget,使高重要性的文件保留更多 token。
4. 子序列恢復(Subsequence Recovery)
- 壓縮後可能導致命名實體缺字、錯字。
- 根據 LLM 回答中出現的 token 子序列,對應回原始 prompt 補全缺失內容,確保回覆正確性與可讀性。
實作與效果
- 搭配模型:壓縮階段使用 LLaMA-2-7B,應用階段支援 GPT-3.5、LongChat。
- 適用場景:RAG、多文件問答、長文本總結、多跳推理等。
- 效果:
- 可達 4x~6x 壓縮比,性能反而上升(資訊密度提升)。
- 成本最高可省下 94%,延遲加速最高 2.6 倍。