Support Vector Machine (SVM, 支持向量機)
SVM 是一種 Supervised Learning (監督式學習) 的分類/回歸方法
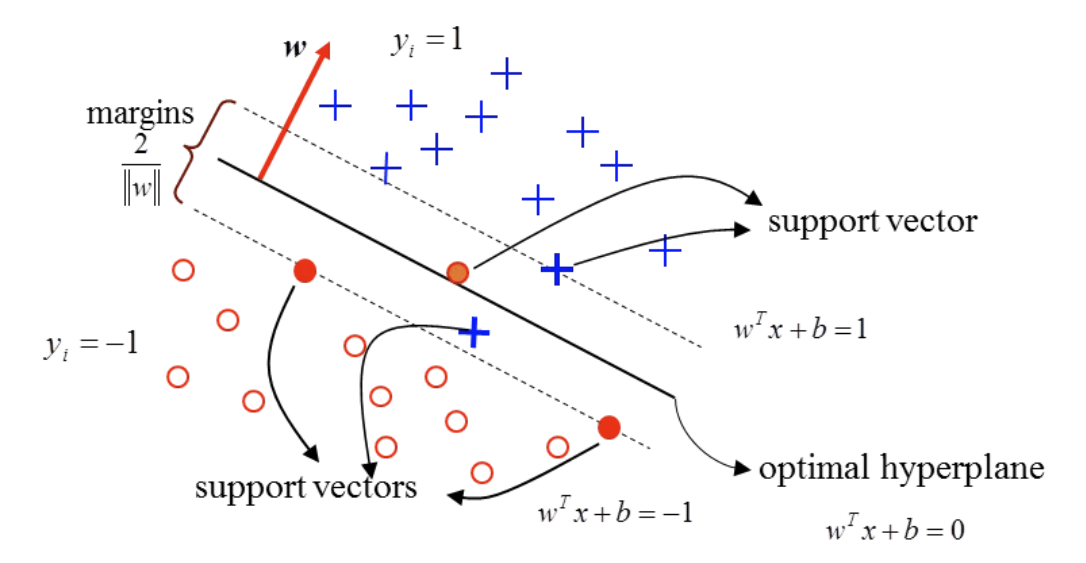
- 核心概念:找到一個分類的 超平面 (hyperplane),讓兩類之間的邊界 (margin) 最大化 → 決策邊界 (decision boundary)。
- 最佳化目標:找到 Optimal hyperplane,讓邊界寬度
最大化。 - 理論基礎:依據「統計風險最小化」(Statistical Risk Minimization) 原則,平衡分類準確率與模型複雜度。
簡單來說:SVM 就是在計算一條(或一個平面)能最佳區隔不同類別的界線,使之將兩個不同的集合分開,並讓距離最近的資料點(support vectors)離邊界越遠越好。
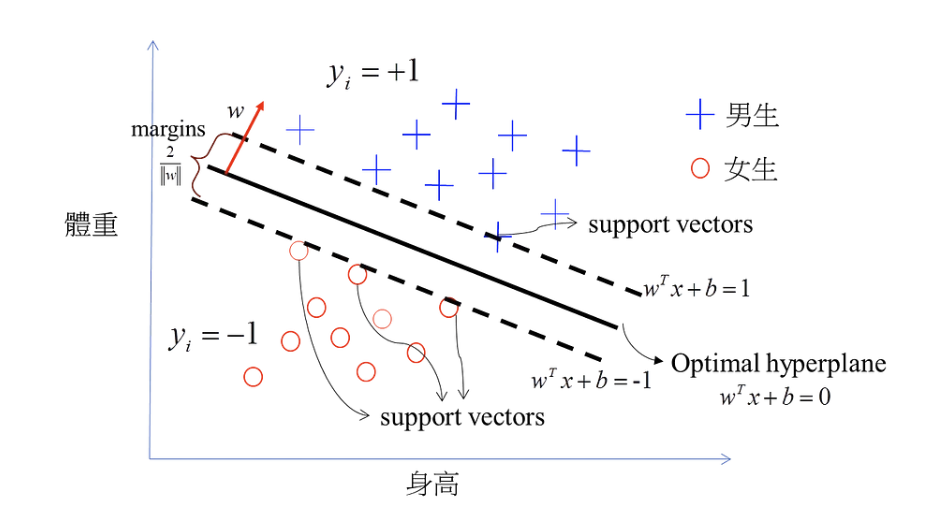
超平面
指在高維中的平面,因為通常訓練和測試的資料都是高維度的資料。
Hard-Margin 與 Soft-Margin ?
- Hard-Margin SVM:要求資料完全可分,所有點都必須在邊界外側。
- Soft-Margin SVM:真實資料通常有雜訊或重疊,允許部分資料點落在邊界內,但會在最佳化中加入懲罰項 (penalty term, ( C )) 來控制允許的錯誤量。
核函數 (Kernel Function)
SVM 不只可用於線性可分的情況,透過 核技巧 (Kernel Trick) 可將資料映射到更高維度,使其在高維空間中變得線性可分:
- 常見核函數:
- 線性核 (Linear Kernel)
- 多項式核 (Polynomial Kernel)
- 高斯 RBF 核 (Radial Basis Function)
- Sigmoid 核
小結
- Support Vectors:真正決定超平面位置的關鍵資料點。
- Margin 越大 → 模型泛化能力越好(不易 overfitting)。
- 可用於分類(Classification)與回歸(SVR, Support Vector Regression)。
AI - Ch17 機器學習(5), 支持向量機 Support vector machine, SVM | Mr. Opengate
機器學習-支撐向量機(support vector machine, SVM)詳細推導