LightRAG - Simple and Fast Retrieval-Augmented Generation
Submitted on 8 Oct 2024
問題與動機
傳統 RAG 存在三個痛點:
- 扁平資料表示:僅靠 chunk embeddings,難以捕捉實體間關聯。
- 上下文意識不足:檢索結果片段化,缺乏整體語意關聯。
- 更新成本高:新知識需重新嵌入與重建索引。
只能搜索局部的問題點,很難思考全域問題
⇒ LightRAG 的目標是將文本轉為圖結構(entity + relation),並結合向量檢索,使模型能快速取得局部與全域知識,同時可增量更新(incremental update)。
文字 → [LLM抽實體+關係] → 建知識圖 →
查詢(拆keyword) → 雙層檢索 → LLM生成答案
核心架構
整體架構分成三大模組
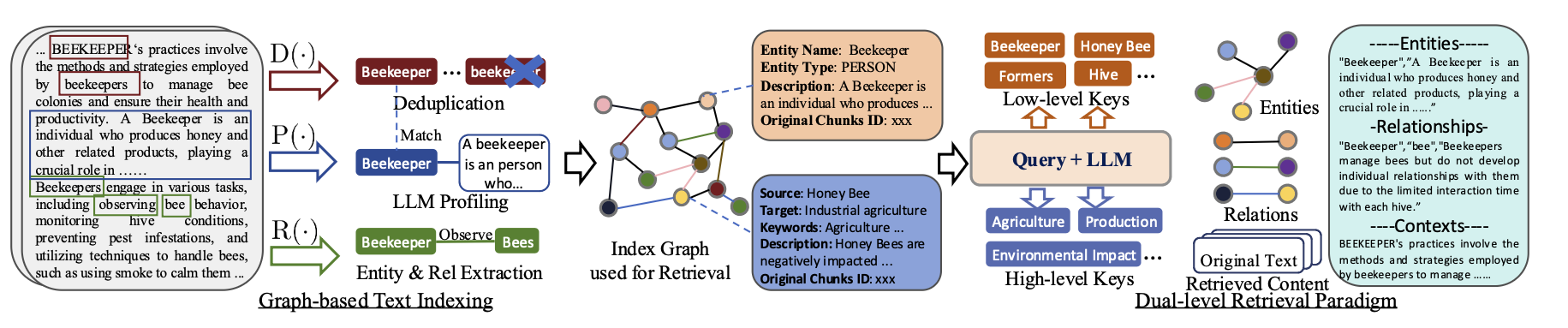
把「一堆文字」變成「一張關係圖」,
讓 RAG 系統能更懂誰跟誰有關,回答更準、更快、也能即時更新。
(1) Graph-based Text Indexing
目標:
- 將原始文件 → 知識圖(Knowledge Graph)
- 把文件切成小段(chunks)
- 用 LLM 抽出:
- 實體 (entity):像「Beekeeper」「Bee」「Honey」
- 關係 (relation):像「Beekeeper 管理 Bees」
- 「圖」,節點是實體、邊是關係
- 建立圖索引
- 幫每個實體和關係生成:
- key(索引標題)
- value(簡短描述)
- 例如:
key: "Beekeeper"value: "A person who manages bee colonies and produces honey."
- 把重複的實體合併,讓圖更乾淨。
詳細步驟:
- 實體與關係擷取
R(·)- 使用 LLM(如 GPT-4o-mini)抽取 entity、relation
- e.g., 從 “Cardiologists assess symptoms…” 得出節點與邊:
("Cardiologists") → (diagnose) → ("Heart Disease")
- LLM Profiling(生成 key-value)
P(·)- 每個 entity/relation 生成檢索用 key 與內容 value
- e.g., key:
"Cardiologist", value: 簡述該職業與功能 - Relation 會擴充 global key(如「Healthcare」主題)
- Deduplication
D(·)- 合併重複節點與邊,降低圖的冗餘度
最終得到
D̂ = (V̂, Ê):包含所有文件的知識圖節點與邊。
優點:能做 multi-hop reasoning(多跳檢索)與全域語意聚合。
(2) Dual-level Retrieval Paradigm
目標: 根據查詢類型(細節/概念),執行雙層檢索
低階檢索(Low-Level Retrieval)
- 對應具體問題,如「Who wrote Pride and Prejudice?」
- 聚焦特定 entity 與直接關聯的 edges
- 檢索結果包含精確細節(人名、年份、事件)
高階檢索(High-Level Retrieval)
- 對應抽象問題,如「How does AI influence education?」
- 聚合多個節點與關聯,形成主題層次語意(多跳整合)
實作流程:
- Query Keyword Extraction
- 從 query 中萃取兩組關鍵詞:
k(l):local keywords(具體實體)k(g):global keywords(主題/抽象概念)
- 從 query 中萃取兩組關鍵詞:
- Keyword Matching
- 使用 vector DB(Nano VectorDB)比對:
- local → entity 節點
- global → relation/主題邊
- 使用 vector DB(Nano VectorDB)比對:
- High-order Relatedness 擴展
- 取出檢索節點的 1-hop 鄰居
{vi ∈ Nv ∨ Ne} - 增加上下文豐富度
- 取出檢索節點的 1-hop 鄰居
→ 結果是兼具細節準確與語意廣度的檢索集合
(3) Retrieval-Augmented Answer Generation
步驟:
- 取得檢索結果 ψ(q; D̂),整合各節點與關係的 value。
- 將 query + 檢索文本餵入 LLM。
- LLM 生成具上下文連貫與全域視角的回答。
關鍵差異:
- 傳統 RAG:拼接多個 chunks
- LightRAG:拼接多個「關聯節點描述」+「關係摘要」
→ 結果更精簡、更具知識結構。
三、增量更新(Incremental Update)
目標:快速整合新知識而不重建索引
當有新文件 D′:
- 使用同樣的 φ 流程建構圖 D̂′
- 將舊圖與新圖 union:
- V̂ ← V̂ ∪ V̂′
- Ê ← Ê ∪ Ê′
優點:
- 保留舊關聯,僅增補新節點與邊
- 無需重跑 embeddings,更新效率高