Decision Tree (決策樹)
Decision Tree 是一種樹狀結構模型。
它透過「反覆切分資料」來做預測,直到滿足終止條件。
每個節點(node)會問一個問題,例如:
- 年齡 > 30?
- 收入 > 50k?
資料依答案走向不同分支,最後到葉節點(leaf)得到預測結果。
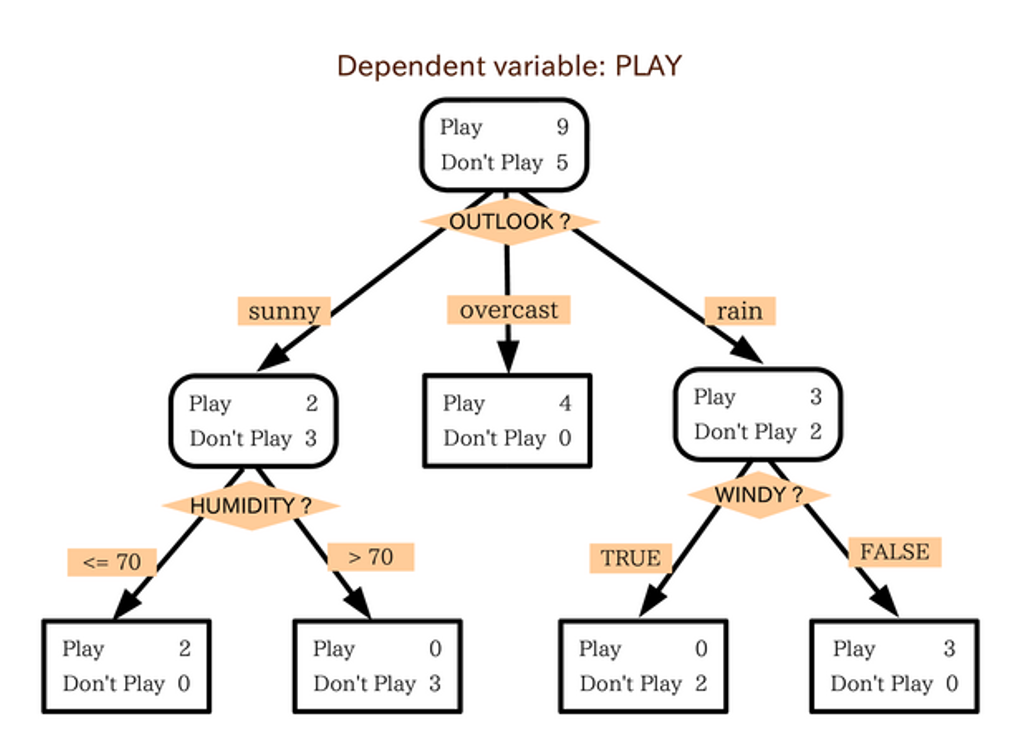
可以做什麼
- 分類(Classification)
- 回歸(Regression)
- 特徵重要性分析
- 規則萃取(if-then 規則)
切分準則(怎麼選問題)
常見做法是每一步都選「切完最純」的特徵:
- 分類常用:Gini impurity、Entropy / Information Gain
- 回歸常用:Mean Square Error, MSE (均方誤差)
為什麼 Decision Tree(回歸)常用 MSE?(白話)
-
MSE 就是在算「平均錯多少」
預測值和真實值差越大,分數越差。 -
樹在每次切資料時,需要一個「評分標準」
MSE 可以幫它比較:
「這樣切」跟「那樣切」,哪個讓錯誤更小。 -
回歸樹葉節點通常用平均值當預測
而「用平均值」剛好就是讓 MSE 最小,彼此很搭。 -
MSE 會特別在意大錯誤
因為有平方,所以大錯會被放大。
好處是模型會更努力修正明顯錯誤。
Note
如果資料裡離群值很多,MSE 可能太敏感;
可以考慮用 MAE(平均絕對誤差)當替代。
優點
- 可解釋性高(路徑就是決策規則)
- 幾乎不需要特徵縮放
- 能處理數值與類別特徵
- 可捕捉非線性關係
限制
- 容易過擬合(overfitting)
- 對資料擾動敏感,穩定性較差
- 若樹太深,泛化能力容易下降
如何減少過擬合
- 限制最大深度(max depth)
- 設定最小樣本切分數(min samples split / leaf)
- 後剪枝(pruning)
- 改用集成方法:Random Forest (隨機森林)
與 Random Forest 的差異
- Decision Tree:單棵樹,解釋性高,但波動大
- Random Forest:多棵樹投票,通常更穩定、泛化更好