Guardrail AI
Safe and reliable AI via guardrails - DeepLearning.AI

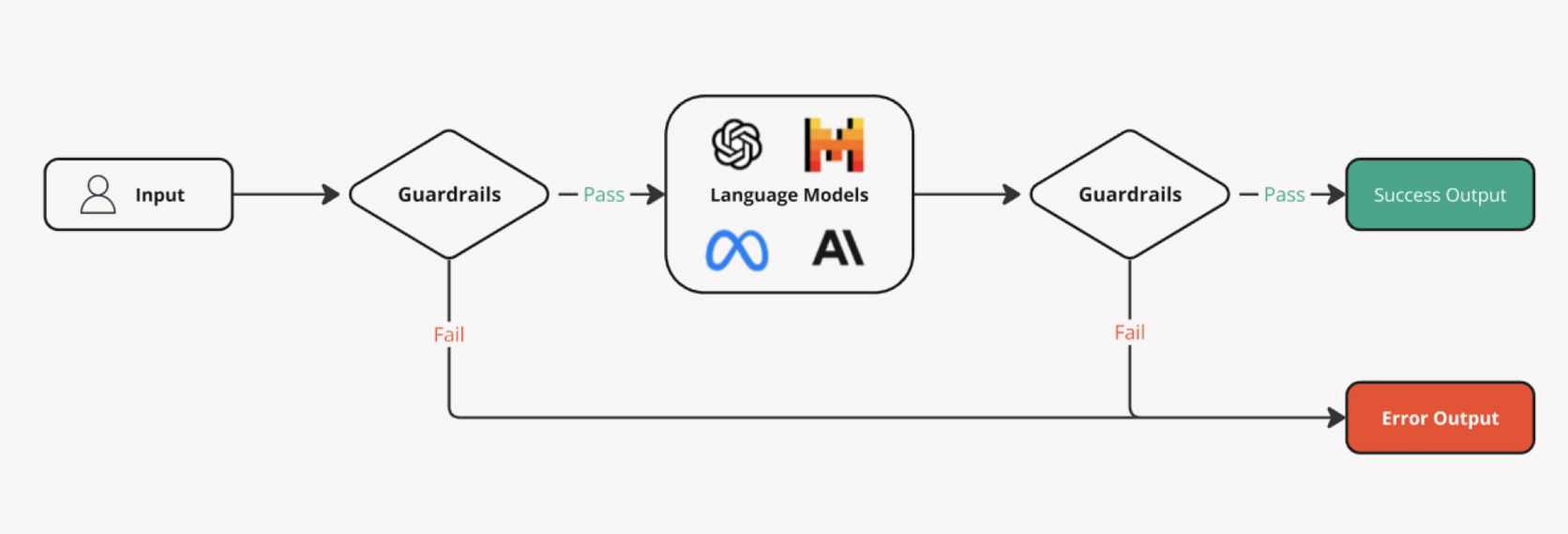
企業導入 LLM 時,不能只靠模型本身安全,還需要在輸入與輸出層加上 Guardrails,作為額外的安全分類與阻擋機制。
Topic: LLM Guardrail
Guardrails AI
這間公司: Guardrails AI
專門做 GenAI Reliability / AI Assurance 的公司 ⭢ AI Reliability Platform
主要是希望在環境部屬時,可以增加「防護與驗證層」
Docs: Overview - Guardrails AI
常見風險
| 類型 | 意思 |
|---|---|
| Toxic speech | 仇恨、歧視、冒犯、暴力內容 |
| Data privacy violations | 模型輸出洩漏敏感或專有資料 |
| Operational failures | 關鍵業務流程出錯,例如金融、客服、安全場景 |
| Regulatory non-compliance | 違反產業法規、偏見與公平性要求 |
核心產品
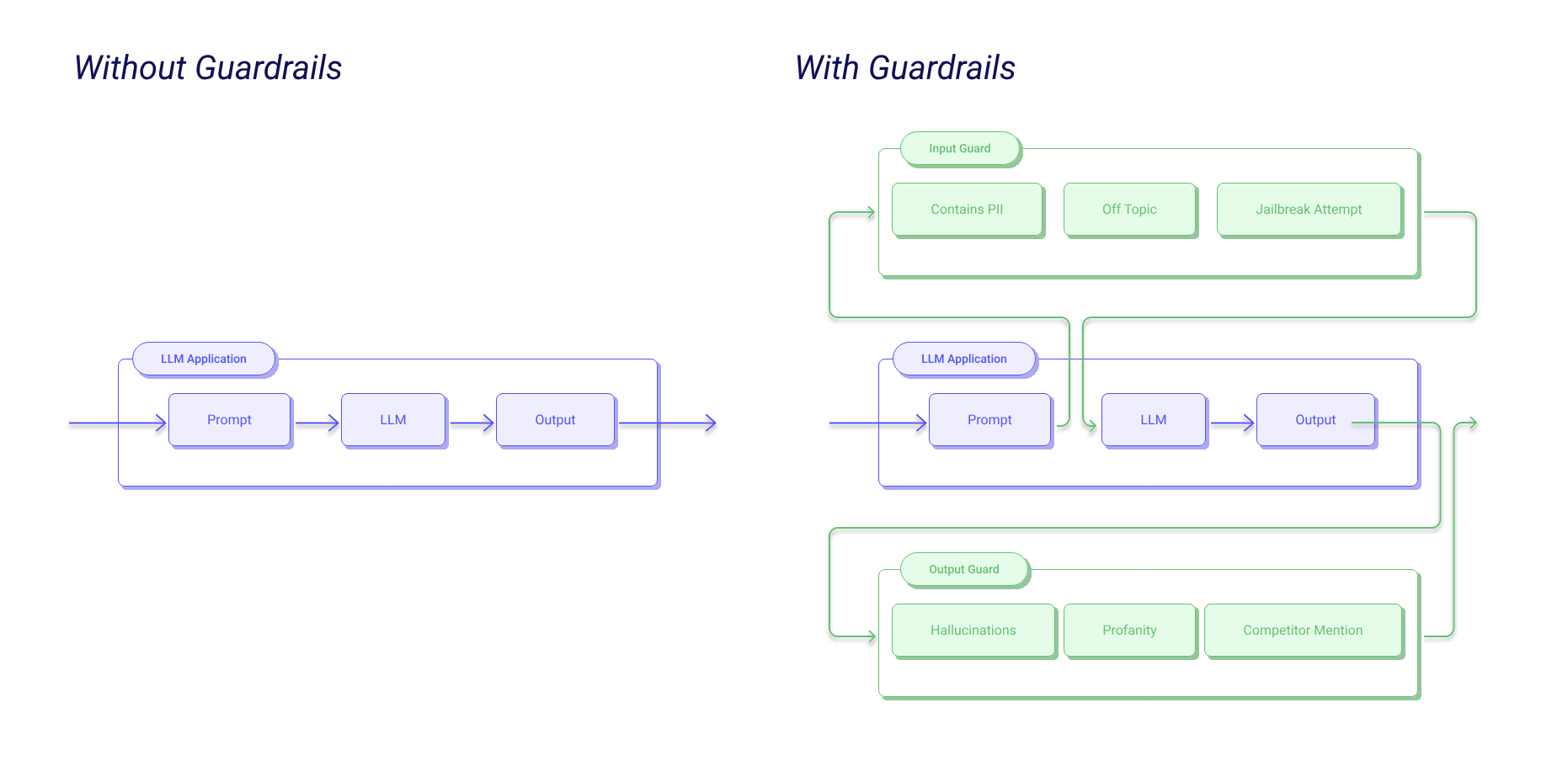
用來替 LLM 應用加入 Input / Output Guards,偵測、量化與緩解特定風險,同時也支援讓 LLM 產生結構化資料。
GitHub - guardrails-ai/guardrails: Adding guardrails to large language models. · GitHub
這堂課的核心價值
⇒ 建立 Validator(驗證器)
Validator 用來檢查 LLM input / output 是否符合規則
常見判斷方式:
- Regex / Rule-based
- Classifier
- Schema Validation
- LLM-as-a-Judge
- Embedding Similarity
- Provenance / Citation Check
其他相似產品: Webex
放置位置:
- Input Guard:模型前檢查
- Output Guard:模型後檢查
AI Guardrails: Ensuring Safe and Reliable Language Model Deployment
防哪些問題?
| 類型 | 做什麼 |
|---|---|
| 安全防護 | 偵測 jailbreak、unsafe prompt、NSFW、toxic language |
| 資料外洩防護 | 偵測 / 遮罩 PII,例如 email、電話、姓名等 |
| RAG factuality | 檢查回答是否被來源文件支持,降低 hallucination |
| 格式驗證 | 確保 JSON、SQL、Python、URL、OpenAPI schema 合法 |
| 品牌 / 合規控制 | 禁詞、競品名稱、偏見語句、語言一致性 |
| 結構化輸出 | 讓模型輸出符合 Pydantic / JSON schema |