How Instacart Built a Search for Billions of Products
閱讀: How Instacart Built a Search for Billions of Products
原文: How Instacart Built a Modern Search Infrastructure on Postgres
發展
Instacart 搜尋同時面對兩種 retrieval 需求:
- 精確商品查詢:
例如「pesto pasta sauce 8oz」,適合 keyword / full-text retrieval - 模糊語意查詢:
例如「healthy foods」,需要 semantic retrieval 理解使用者 intent
-
Elasticsearch
早期作為 keyword / full-text search 系統,適合關鍵字搜尋與 BM25 排序。 -
Elasticsearch → PostgreSQL
將 full-text search 遷到 sharded PostgreSQL,並用正規化資料模型管理 price、availability、ML features 等高頻變動資料。
好處是降低 indexing / write workload,也讓資料維護更簡單。 -
PostgreSQL + FAISS
PostgreSQL 負責 keyword search,FAISS 負責 semantic vector search。
但兩套 retrieval system 要同步資料,且 FAISS 對 retailer、庫存等 metadata filtering 支援有限。 -
PostgreSQL + pgvector
將 semantic search 也整合回 PostgreSQL。
好處是 keyword search、vector search、庫存過濾、ranking features 可以放在同一個資料層處理,降低系統複雜度並改善 recall。
Elasticsearch
早期 Instacart 使用 Elasticsearch 作為 full-text search 系統
是當時常見的 full-text search 方案(industry-standard)
ByteByteGo 摘要中也提到它適合大規模 keyword search,並使用 BM25 這類成熟 ranking 機制
但 Instacart 的問題在於資料變動非常頻繁:
價格、庫存、折扣一天內會多次更新
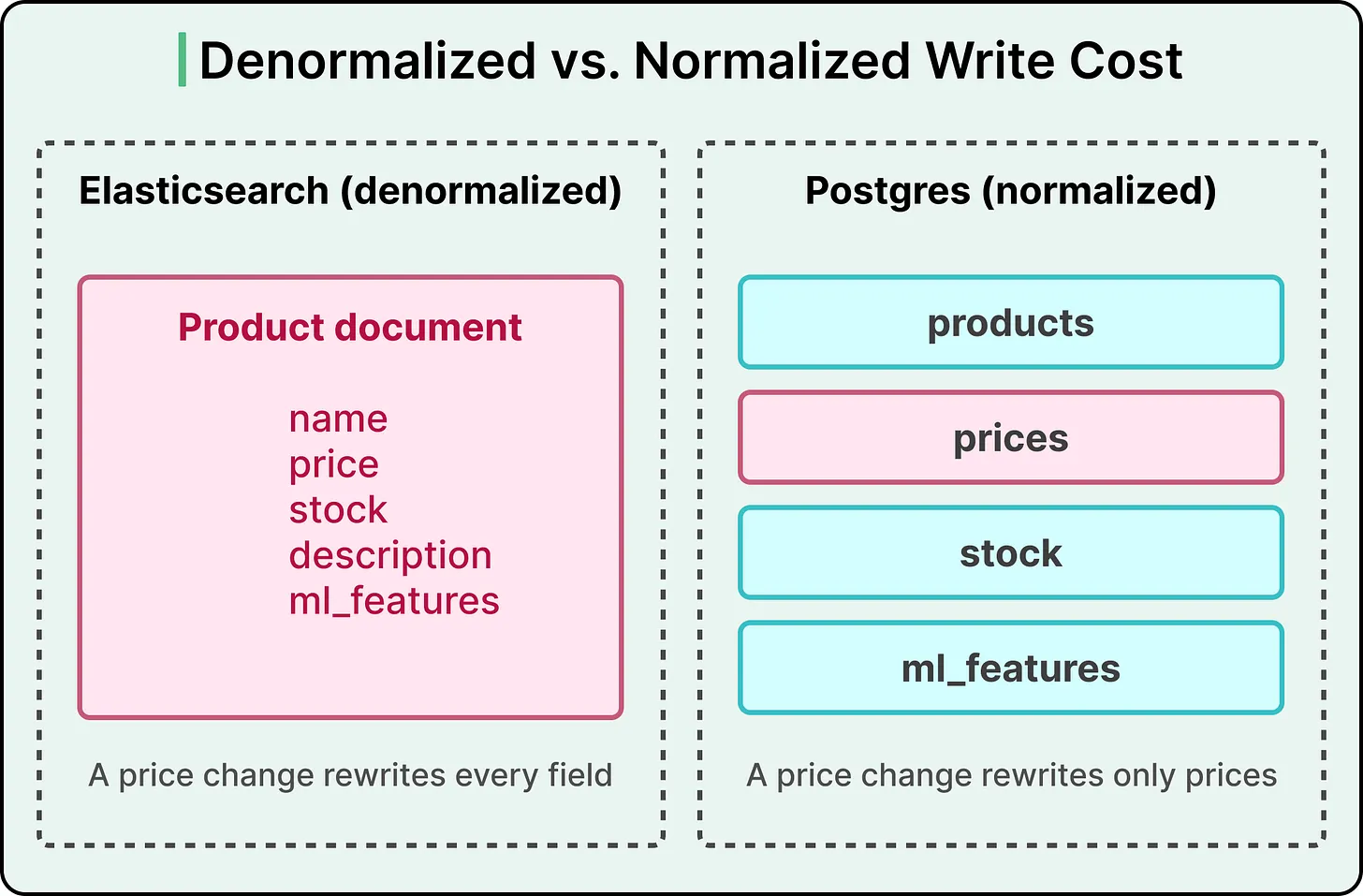
Elasticsearch 偏向 denormalized document
單一欄位變動也可能需要重寫整份 document,導致 indexing load 過高
PostgreSQL
後來 Instacart 將 full-text search 從 Elasticsearch 遷移到 sharded Postgres,並改成高度正規化的資料模型。透過 Postgres GIN index 與 modified ts_rank,Instacart 可以在 Postgres 內完成文字匹配。
正規化資料模型讓 price、availability、ML features 分散在不同 table,各自用不同頻率更新,不必每次都重寫整份搜尋 document。
結果:
- write workload 降低約 10x
- storage / indexing 成本下降
- 可以把數百 GB 的 ML features 放在 documents 旁邊
- 透過 bring compute to data,減少 network calls、overfetching 與 application-layer join
- Postgres-based search latency 約提升 2x
混合系統階段:Postgres + FAISS
Postgres 解決 keyword / full-text retrieval 後
Instacart 又加入 semantic search
當時 Postgres 尚未成熟支援 ANN search,所以 Instacart 用 Meta 的 FAISS 建立 standalone semantic retrieval service
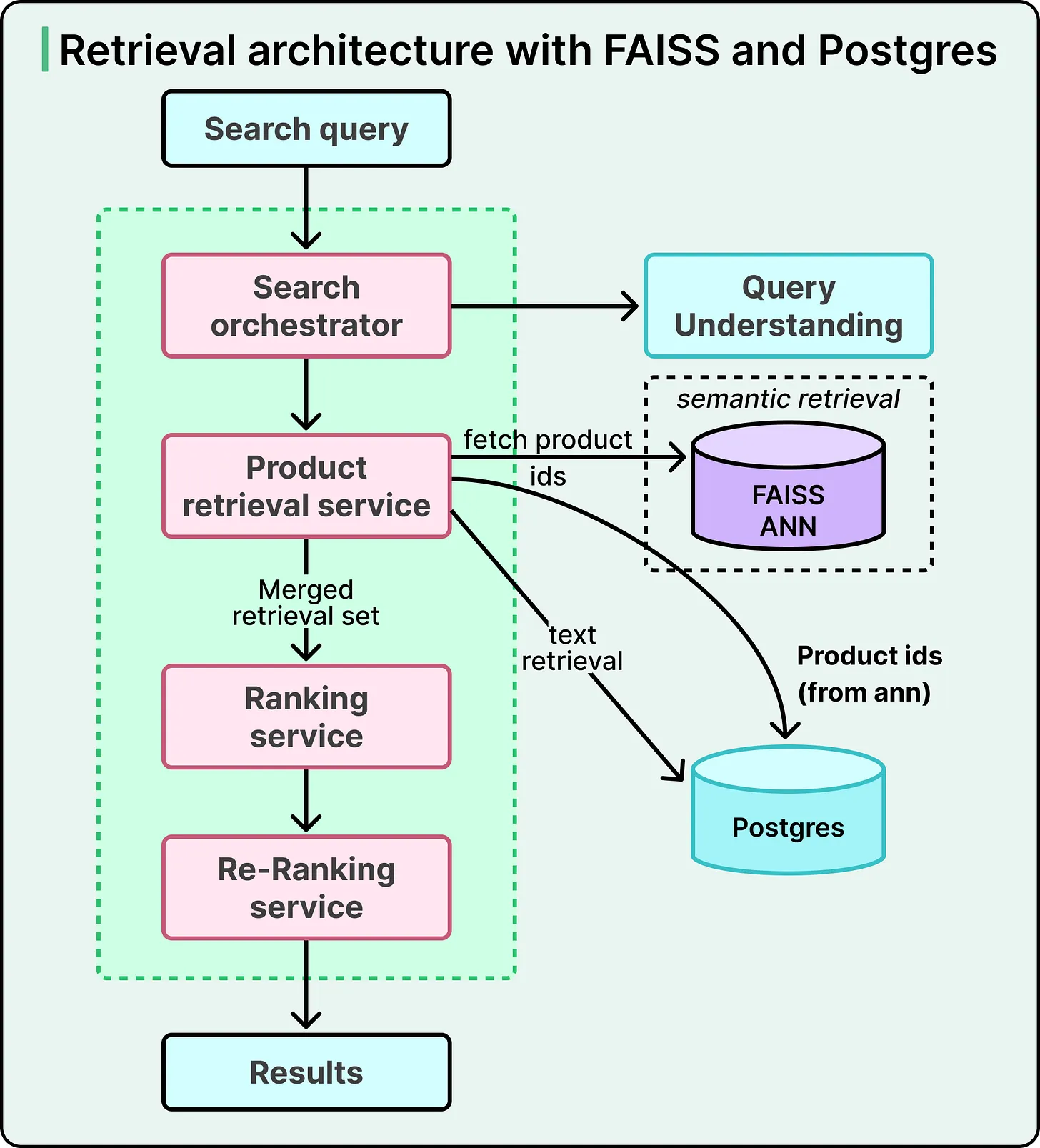
架構:
- 每次 query 會平行查詢 Postgres 與 FAISS
- 再由 application layer 用 ranking model 合併結果
- 接著送到 ranking / reranking layers
- Embedding model:bi-encoder(HuggingFace MiniLM-L3-v2 架構)產生 query embedding 與 document embedding
- Retrieval:Postgres 做 full-text,FAISS 做 ANN;application layer 合併兩邊結果
問題:
- FAISS 對 attribute filtering 支援有限 → 需要 overfetch 後再 post-filter,相關商品可能在 post-filter 前就沒被抓到
- 兩套 retrieval system 需要同步資料,operational burden 增加
- keyword signal 與 semantic signal 不容易細緻整合
Pgvector
Pgvector 是 Postgres 的 vector search extension
可以讓 semantic search 也整合進 Postgres
核心價值:
- keyword search 與 semantic search 統一在同一個 datastore
- 可以在 ANN search 前先用即時庫存做 pre-filter,避免 FAISS 時代 overfetch + post-filter 的問題
- recall 更好 → zero-result searches 下降約 6%
- 減少資料同步與雙系統維護成本
pgvector 的價值不是「比 FAISS 更快」
⇒把 semantic search 也整合回 Postgres
不論什麼搜索都會有 Approximate Nearest Neighbor Search Instability