SequenceMatcher
SequenceMatcher 來自 Python 標準庫 difflib,
是序列比對工具,常用於 diff、模糊比對前處理、近似重複檢測。
重點:
- 不只可比對字串,也可比對任意序列(元素可 hash)
- 可計算相似比率、匹配區塊、差異操作序列
- 偏向表面形式對齊,不是語義理解工具
不只比對字串
除了字串,也能比對 list / token 序列:
from difflib import SequenceMatcher
a = ["我", "喜歡", "NLP"]
b = ["我", "很", "喜歡", "NLP"]
sm = SequenceMatcher(None, a, b)
print(sm.ratio())
核心機制(更精確)
SequenceMatcher 會尋找兩個序列中的最長連續匹配區塊,
並在前後區段遞迴比對,最後彙整為整體相似度與差異操作。
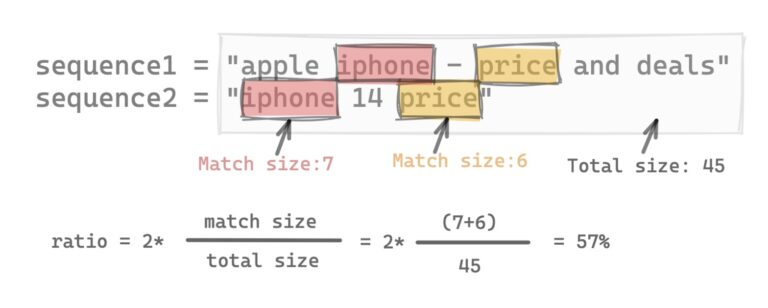
ratio() 是什麼,不是什麼
概念公式:
M:匹配元素總數T:兩序列元素總數
注意:
- 這不是 Levenshtein 編輯距離
- 這不是語義相似度
- 這是依據匹配區塊計算出的相似比率
常用 API
ratio()
- 回傳 0 到 1 的相似度分數
- 在部分情況下可能受輸入順序影響(非嚴格對稱)
get_matching_blocks()
- 回傳匹配片段
(a_idx, b_idx, size) - 最後會附帶哨兵
(len(a), len(b), 0) - 匹配單位取決於輸入序列:
- 字串輸入 -> 多為字元級
- token list 輸入 -> token 級
get_opcodes()
- 回傳
equal / replace / insert / delete - 可用於標註差異或後續修正流程
- 不保證是最短編輯路徑(not guaranteed minimal edit script)
autojunk(實務常見坑)
SequenceMatcher 預設 autojunk=True。
在長序列中會忽略部分過度常見元素,避免比對過慢或失真。
若需要更可控、可重現的行為,可關閉:
SequenceMatcher(None, a, b, autojunk=False)
Python 範例(字串)
from difflib import SequenceMatcher
a = "I like machine learning"
b = "I love machine leaning"
sm = SequenceMatcher(None, a, b, autojunk=False)
print("ratio:", sm.ratio())
print("matching blocks:", sm.get_matching_blocks())
print("opcodes:")
for op in sm.get_opcodes():
print(op)
ratio: 0.87... # 依輸入內容而定
("equal" / "replace" / "delete" / "insert" ...)
什麼情境好用
- 文件版本比對前的粗匹配
- 欄位名、標題名近似合併
- OCR / ASR 後處理候選比對
- 模板與回覆去重(near-duplicate detection)
限制與注意事項
- 屬於序列層面的形式比對,不等於語義相似
- 切分方式(字元級 vs token 級)會明顯影響結果
- 在部分資料分布下,
ratio()可能受輸入順序與autojunk影響 - 大規模長文本比對可能偏慢
視覺化與參考
可以看到有被比對到的區塊: