Automated Peer Reviewing in Paper SEA-Standardization, Evaluation, and Analysis
| type | url |
|---|---|
| Paper | 2407.12857 |
| HomePage | Automated Peer Reviewing in Paper SEA: Standardization, Evaluation, and Analysis |
| Code | GitHub - ecnu-sea/SEA |
| Model | ECNU-SEA/SEA-S · Hugging Face |
| Conference | EMNLP2024 |
Abstract
目前的自動化審查方法大多依賴 LLMs ,但生成的內容較為泛泛或不完整,所以他們介紹了 SEA 框架,這之中包含三個模組:
- Standardization (SEA-S)
- 使用 GPT-4 整合多篇審查審查並進行數據標準化
- Evaluation (SEA-E)
- 生成具建設性的審查意見
- Analysis (SEA-A)
- 透過自我修正機制改善論文內容與審查意見的一致性
Introduction
研究出版物的數量大幅增加,但傳統的審查機制帶來挑戰:
- 給傳統科學審查機制對同行評審的壓力
- 大量出版物導致品質參差不齊
→ 需要自動化科學審查機制,但現有方法的生成內容往往過於通用,缺乏深度和一致性,無法提供有價值的審查意見
Traditional language models typically struggle to handle such lengthy texts, let alone provide valuable review insights (Cohan et al., 2020; Wang et al., 2020). #cite
目前的自動化審查機制中, LLMs 處理長文本的進步帶來了可能性,並在許多任務中取得不錯的表現,但仍有許多問題:
- 簡單提示工程 (Simply prompting LLMs)
- 為了廣泛應用而設計,這可能導致生成的審查意見過於通用或缺乏深度
- 同儕審查數據集並對 LLMs 微調
- 這些審查可能存在偏見、片面、格式不統一,限制了 LLMs 的潛力
- !審查機制的綜合應用.png
- 現有方法缺乏自我修正機制,無法改善不一致或低質量的審查意見
為了解決上述問題,提出新的自動化論文審查架構 SEA (Standardization, Evaluation, and Analysis):
- 標準化模組 (SEA-S)
- 收集同一篇論文多篇審查意見,
- 透過 GPT-4 整合成統一格式(包含優點缺點),變成 SFT 數據集
- 提煉 GPT-4 的知識,透過 Mistral-7B 進行微調
- 輸出為標準的評論審查格式
- 評估模組 (SEA-E)
- 解析 PDF 文件
- 利用 SEA-S 模組標準化處理的審查數據集,透過 Mistral-7B 微調訓練
- 輸出為分析論文和生成高品質評論
- 分析模組 (SEA-A)
- 自我修正機制,生成的審查與論文不一致時,進行重新生成,並使用 mismatch score 測量不一致性
.png)
Related Work
LLMs 在長文本中取得實質性的成長
support long contexts processing by modifying the attention mechanism:
LLMs 處理 long contexts 的能力:
- The needle-in-a-Haystack (NIAH) test (Kamradt, 2023) has been widely adopted to evaluate long-context LLMs. #cite
SEA
Standardization, Evaluation and Analysis
SEA-S: Standardization
在自動化科學審查機制中需要高品質的標注數據集進行 Supervised Fine-tuning (SFT) ,然而不同的審查者意見通常基於自身的專業領域,格式和標準也不同,導致不一致性。
解決方法 → 將多個審查意見整合成統一格式,消除重複和錯誤,並專注於論文的主要優點和缺點
訓練時選擇的模型比較 Mistral-7B、GPT-3.5 和 GPT-4:
- Mistral-7B 和 GPT-3.5 只是簡單地串連原始內容
- → 不好
- GPT-4 能將審查意見整合成統一格式,並提供詳細證據
- → 好,但太貴且靈活不夠
- → 因此使用 GPT-4 的整合能力進行知識提取,應用於 Mistral-7B
訓練
對於每個論文(
為訓練集(20%)的論文數量 為那篇論文的評論數量 - → 結合為三元數據集
用於當作 SFT 的訓練資料集,訓練 SEA-S
透過 SEA-S 輸出的評論為
- N 為訓練集的論文數量
SEA-E: Evaluation
因為爬取的格式是 PDF format ,所以透過 Nougat 工具解析成 LaTeX Code ,避免文本編碼錯誤,使模型更深入理解論文內容 →
Nougat是一个强大的OCR工具,基於 Visual Transformer,專門用於學術文檔解析,尤其能將公式解析成 LaTeX 代碼
考慮到論文屬於長文本資料,選擇 Mistral-7B 作為主要模型,該模型能處理 16K tokens 的長文本,在長上下文基準 RULER 測試中表現良好
用於 SEA-E 的資料集:
數據集使 SEA-E 經過微調後,具備生成全面且建設性審查的能力
SEA-A: Analysis
- Ground-truth paper ratings
: 代表來自每個評審的評分集合 是某位審查者給出的評分
- Confidence scores
: 代表每個評審的信心分數集合 是某位審查者對其評分的信心程度
- Weighted Average
- 計算論文的加權平均評分,使用評審的信心分數作為權重
Mismatch Score(不一致分數)
用來衡量論文與其生成審查之間的一致性
- 當 Mismatch Score > 0 時,強調優點;反之缺點
- 當 Mismatch Score = 0 時,表示評論相對中立且與論文內容一致
- 當 Mismatch Score 越大或越小,表示該審查者的評分與其他人的評分偏差較大,代表該審查意見的質量可能較低
SEA-A 回歸模型訓練
- 文本向量化
- 使用由 SEA-E 生成的
作為輸入 - 使用預訓練的 SFR-Embedding-Mistral 模型生成向量
- 論文向量 →
- 評論向量 →
- 論文向量 →
- 使用由 SEA-E 生成的
- 計算 Query 和 Key 向量
- 預測 Mismatch Score
為論文的 Query 與評審的 Key 內積,代表相關性 為評審的 Query 與論文的 Key 內積,代表相關性
- 評估
- 使用均方誤差(MSE)損失函數來訓練 SEA-A 模型
- 絕對值越小,表示審查與論文的一致性越高
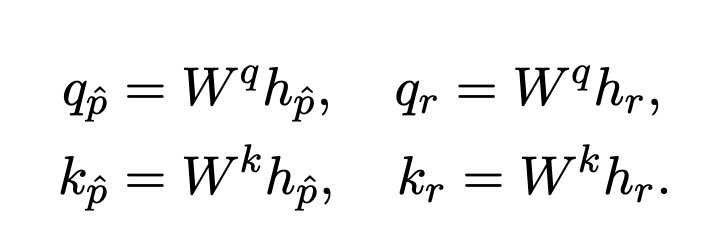
自我修正策略
- 當 Mismatch Score 小於預設閥值
,會重新生成 review - 塞入當前 Mismatch Score 作為額外提示,確保更高的一致性
Experiments
Experimental Details
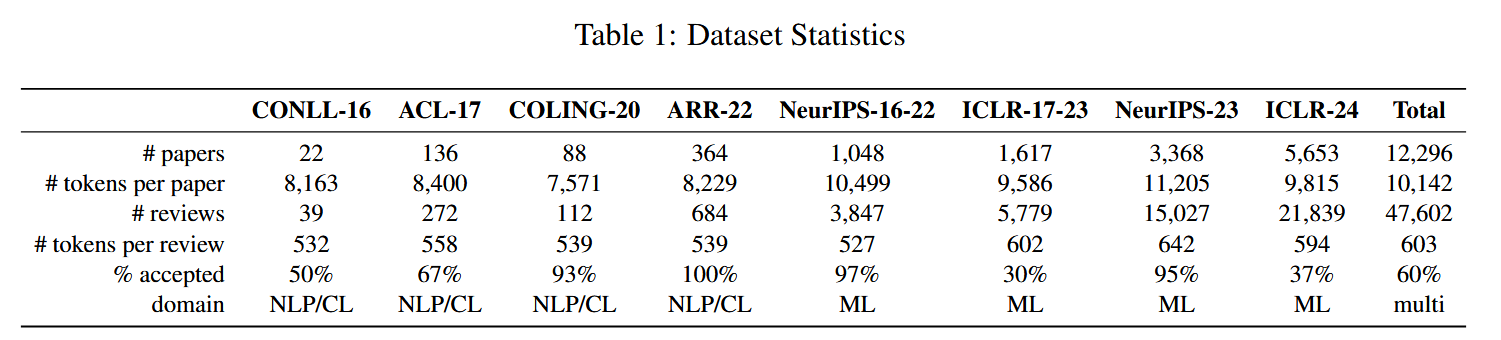
Dataset
All the datasets include the original PDF files of the papers and structurally formatted reviews.
- OpenReview 1, including NeurIPS-2023 and ICLR-2024.
- REVIEWER2 (Gao et al., 2024) for NeurIPS (2016-2022) and ICLR (2017-2023).
- A Dataset of Peer Reviews (PeerRead) - Collection, Insights and NLP Applications (Kang et al., 2018) for CONLL2016 and ACL-2017
- NLPeer (Dycke et al., 2022) for COLING-2020 and ARR-2022
Setup
使用 Mistral-7B-Instruct-v0.2,上下文可以包含 32k
在評估模組中,評論會包含三個部分:
- Textual Part(文本)
- Quantitative Part(量化)
- Decision Accept/Reject (決策)
設定的部分:
- 訓練 80%, 測試 20%
- 設置
,如果重新生成又超過 10次則被視為失敗,終止
有兩個方法可以產生 Reviews :
SEA-E, SEA-EA(就是在 SEA-E 的基礎下加上 Analysis module)
Baselines
- Direct inference with LLMs
- 使用未經微調的 Mistral-7B 模型來直接推理
- 給模型統一指令 (
),依賴於模型本身的內在能力,沒有進行針對具體任務的調整或微調
- SFT methods
- Mistral-7B-Random (M-7B-R)
- 隨機選擇一個現有的評審作為輸出,品質波動較大
- Mistral-7B-GPT-3.5 (M-7B-3.5)
- 透過 GPT-3.5-turbo 進行標準化,接著進行微調,用於統一評審格式
- REVIEWER2 (Gao et al., 2024)
- 考慮到耗時問,使用較小的數據集進行實驗
- Mistral-7B-Random (M-7B-R)
Main Results
使用不同的指標來對生成的 Reviews 進行評估:
- BLEU, ROUGE(Recall-Oriented Understudy for Gisting Evaluation)
- 使用 n-grams 衡量 papers 和 reviews 之間的相似性
- ROUGE-1: 單字重疊,檢查關鍵字覆蓋情況
- ROUGE-2: 兩連詞重疊,檢查詞組匹配
- ROUGE-L: 最常公共子序列重疊,文本整體結構和語意相似度
- 使用 n-grams 衡量 papers 和 reviews 之間的相似性
- BERTScore
- 判斷向量空間中的相似性
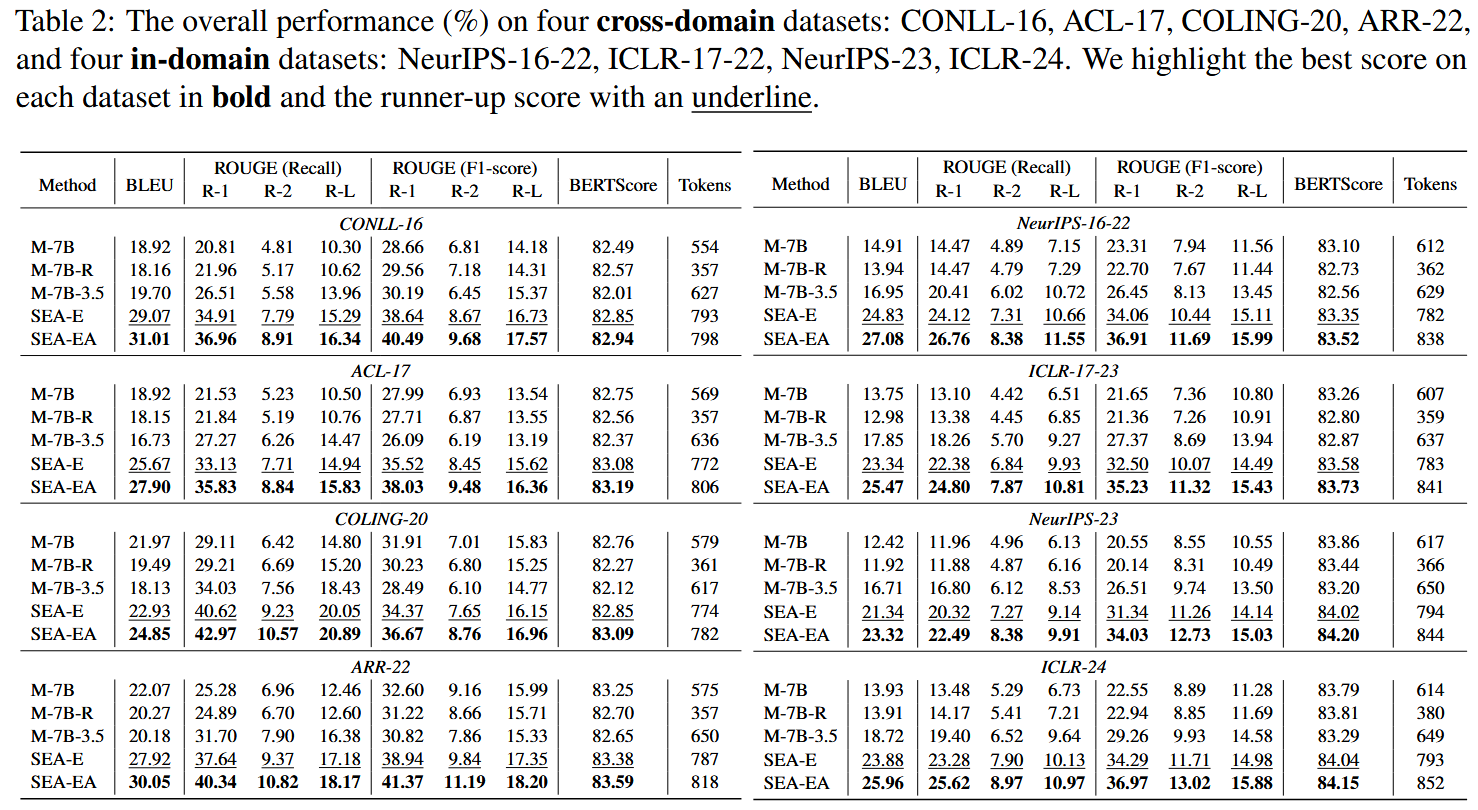
SEA 在所有測試場景中,都優於其他 baseline 模型:
- SEA 方法更能生成高品質 Reviews
- SEA-EA 加入 Mismatch Score 更能生成精確和一致性的 Reviews
Comparison of Standardized Results
Standardized results on papers in the training set of NeurIPS-2023 and ICLR-2024 that have different rating criteria.
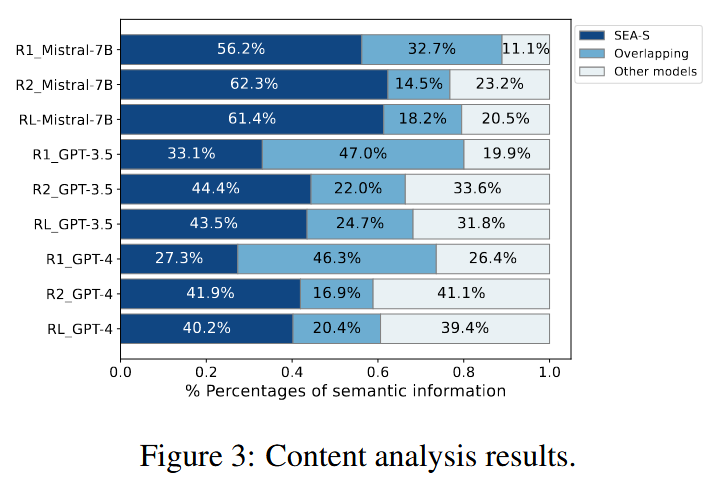
Content analysis
模型選擇 SEA-S、Mistral-7B、GPT-3.5 和 GPT-4 作為比較
標準化任務沒有 Ground-Truth 文本,因此採用以下:
- 使用 SEA-S 作為 reference
- 其他模型的作為 candidates
SEA-S 生成獨有內容多餘 Mistral-7B 和 GPT-3.5,還比 GPT-4 略多一點,這表明 SEA-S 能更好地進行評審標準化並提供更多的信息
Format analysis
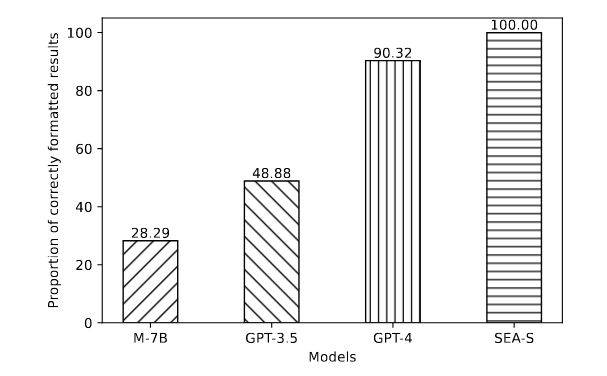
標準化數據對於 LLMs 進行 SFT 時,可以更有助於生成內容之間的對應關係,為了判斷是否可以按照指令輸出正確格式,使用 Regular Expression 來匹配計算不同模型的格式正確率
- SEA-S: 100% 符合要求
- Mistral-7B, GPT3.5: 表現較差
- GPT-4: 約 10 % 沒有服從指令格式,表現整體不錯
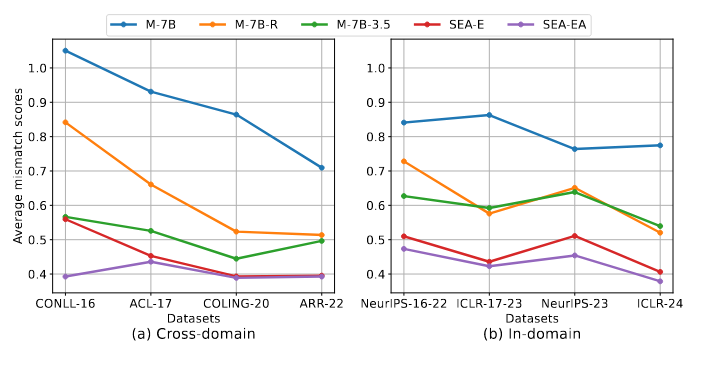
Mismatch Score in SEA-A
透過 SEA-A 計算 Mismatch Score ,輸入:
- 不同模型生成的 Reviews
- 對應論文
結果分析
- SEA-EA 表現最好,SEA-E 是第二名
- Mistral-7B 沒有經過微調,很難學習論文和 Reviews 之間的關係
- M-7B-R and M-7B3.5 雖然進行微調,但仍無法超越 SEA-E 和 SEA-EA
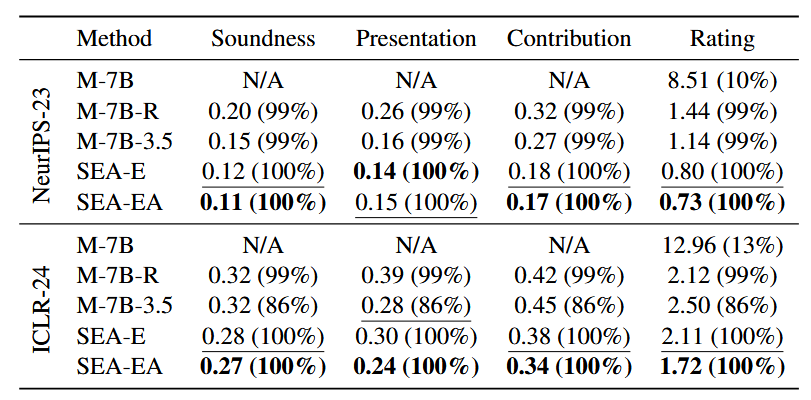
Quantitative Score Analysis
針對生成 Reviews 進行量化分析,包含四個項目:
- Soundness
- Presentation
- Contribution
- Rating
每篇論文有多個評審,要評估上述四個項目,每個分數都有 Confidence 作為權重,計算加權平均分做為參考
- 使用均方誤差 (MSE) 作為評估指標
- 「N/A」表示生成失敗的情況
結論:
- SEA 保證了格式的正確
- 沒有微調的 M-7B 表現很差
- SEA-EA 在大多數情況下相較於 SEA-E 有所提升,證實了自我修正策略能夠在生成結果與人類反饋之間保持高度一致性
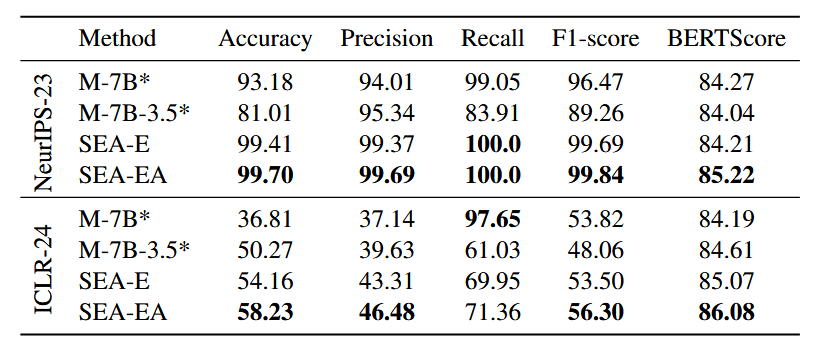
Qualitative Decision Analysis
對於論文中的 Decision 與 Reason 進行分析:
- 透過 Accuracy, Precision, Recall, F1-Score 計算 Decision
- 透過 BERTScore 計算 Reason 與 meta-reviews 相似性
結論
- SEA-EA 在所有指標都表現最好,也證明了自我修正策略的有效
- M-7B 傾向於接受論文,因此精確度較差(迎合大眾)
(*) 代表產生的內容有不完整或錯誤的部分,只計算有效的
Conclusion
- 提出了一個 SEA 的框架,用於自動化論文審稿過程
- 提出一種新的一致性評估指標
- 實驗結果表明 SEA 能與人類評審高度一致
Limitations
- Domain Expansion
- 雖然在機器學習領域中實現了自動化審稿,但是在其他學術領域中還為擴展
- Enhanced Consistency-Guided Training
- 在訓練過程中沒有使用 score ,而為了提高後續 SEA-E 的自我修正階段表現,應該要收集相關數據及提升 SEA-E 內容偏好
- Rebuttal Exploration.
- 未來的研究將探索如何幫助作者撰寫有效的反駁,提升他們在反駁階段的表現
- Ethical Considerations
- 隨著自動化審稿技術的廣泛應用,潛在的濫用風險需要引起重視