RAG, Retrieval-Augmented Generation
LLM 面臨的主要挑戰包括:
- 生成虛假資訊:在無法提供正確答案時,模型可能編造內容
- 資訊過時:回應可能缺乏時效性,無法滿足對最新資訊的需求
- 未授權來源影響:回應可能基於未經授權或不可靠的資料
- 術語混淆:由於訓練來源中術語定義不一致,可能導致回應不準確
Retrieval-augmented generation (RAG) techniques have proven to be effective in integrating up-to-date information, mitigating hallucinations, and enhancing response quality, particularly in specialized domains.
RAG,即檢索增強生成(Retrieval Augmented Generation),是一種結合預訓練大型語言模型與外部數據源的技術。
利用從外部來源獲取的事實來提高生成人工智慧模型準確性和可靠度的技術,以來源屬性呈現準確的資訊。輸出可以包括來源的引用或參考。如果使用者需要進一步釐清或詳細資訊,也可以自行查詢來源文件。這可以增加對生成式 AI 解決方案的信任和信心。
⇒ 結合 資訊檢索 與 生成模型 的技術
主要的優點是可以透過外部知識庫的資訊檢索,獲得相關資訊提供更準確且豐富的答案,使用於知識密集類型的任務。
- 知識更新
- 優點:無需重新訓練模型,只需更新知識庫即可實現知識的即時更新,降低維護成本
- 缺點:倚賴知識庫的品質,若檢索的相關資訊不準確會影響生成解果
- 增強可解釋性
- 由於生成的內容基於可檢索的知識,使用者可驗證答案的準確性,提升對模型輸出的信任度。
What is RAG (Retrieval Augmented Generation) ? | by Vishwajeethogale | Medium
RAG addresses critical gaps in traditional language models, such as outdated or limited knowledge bases.
一般情況下, LLMs 接收使用者傳來的 Query 後根據預訓練時期學期到的知識建立回答,但是可能會造成幻覺、知識落後、專精度不足等問題,為了克服上述情況, RAG, Fine-Tuning 等技術就十分重要。步驟:
- 查詢檢索:使用者提出查詢(Query),檢索模型(Retrieval Model)根據查詢在外部資料庫中搜尋相關內容。
- 向量匹配:查詢被轉換為向量表示,並與向量資料庫進行相似度比對以找到相關文檔。
- 語言模型生成:將查詢與檢索到的相關文檔作為上下文輸入語言模型,生成摘要或回應。
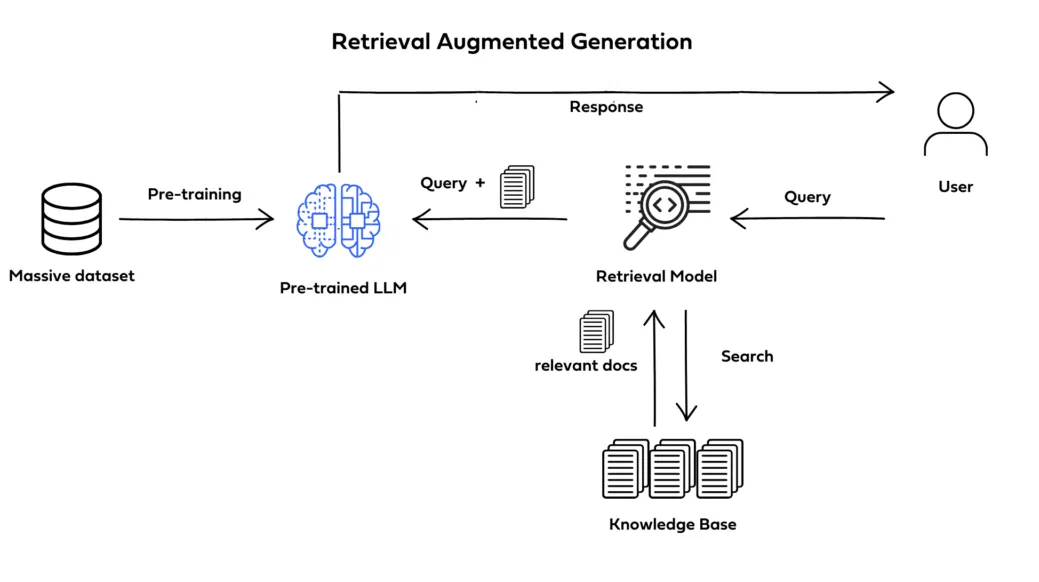
外部資料:
- 定義:外部資料是指 LLM 訓練數據之外的新資料
- 來源與格式:可來自 API、數據庫等
- 支持多種格式(文字、圖像、文件等)
- 處理:透過嵌入模型(Embedding Model)轉換為數值化表示,並儲存在向量資料庫(Vector Database)中以便檢索
- Retrieval-augmented generation (RAG): the breakthrough of 2024 – TensorLoops
- Introduction to Retrieval-Augmented Generation (RAG) and its Transformative Role in AI | by Tarun Singh | Medium
- 查詢向量化:將使用者查詢
轉換為向量表示 。 - 檢索相關文檔:利用檢索模型在外部資料庫中搜尋相關內容。向量資料庫中預存的文檔向量
與 進行相似度比對(如計算餘弦相似度或歐幾里得距離),以選出相關文檔集合 。 - 文檔與查詢結合:將使用者查詢
與檢索到的文檔集合 作為上下文輸入到大型語言模型中,生成回應或摘要:
EmbeddingAlign RAG: Boosting QA Systems
方法
RAG(Retrieval-Augmented Generation)方法通常會通過多個處理步驟來增強大型語言模型(LLMs)的查詢能力,這些步驟包含:
- 查詢分類(Query Classification):判斷當前查詢是否需要進行檢索。
- 檢索(Retrieval):高效地獲取與查詢相關的文件。
- 重排序(Reranking):根據查詢相關性對檢索出的文件進行排序優化。
- 重打包(Repacking):將檢索到的文件組織成結構化內容,以便後續生成。
- 摘要(Summarization):從重打包的文件中提取關鍵信息,消除冗餘,為回應生成提供核心內容。
查詢與檢索轉換(Query and Retrieval Transformation)
為了提升檢索效果,許多方法通過查詢轉換來增強查詢信息:
通過轉換查詢形式來改善檢索性能,提升查詢的準確性與完整性。
檢索器增強策略(Retriever Enhancement Strategy)
-
- 常見的做法是將文件切分為多個片段(chunks)。
- 挑戰:
- 片段過小可能會割裂句子,導致語義不完整。
- 片段過大則可能會包含不相關的上下文,影響檢索效果。
-
重排序(Reranking)
- 在檢索過程中對初步檢索結果進行優化排序的技術,目的是根據查詢的相關性,將最相關的文件或片段排在前面。
- 常用方法是利用深度語言模型(如 BERT [25]、T5 [26] 或 LLaMA [27])進行重排序。雖然重排序步驟推理速度較慢,但能提升檢索性能和準確性。
檢索器與生成器的微調(Retriever and Generator Fine-tuning)
- 檢索器微調:
- 透過微調檢索器,使其能學習檢索對生成器有利的片段,提升生成效果 [33–35]。
- 整合微調:
- 採用整體方法,將檢索器與生成器一起微調,將 RAG 視為一個整合系統。
Embedding Model
- Embedding Model
- Refers to a model specifically designed to learn how to convert raw data (such as text, images, or other types of categorical data) into dense vectors, known as embeddings.
- LLM-Embedder 在效能與模型大小間取得平衡,結果接近BGE-large-en(BAAI/bge-large-en)模型,但LLM-Embedder的大小約為BGE-large-en的三分之一,具有更高效能。
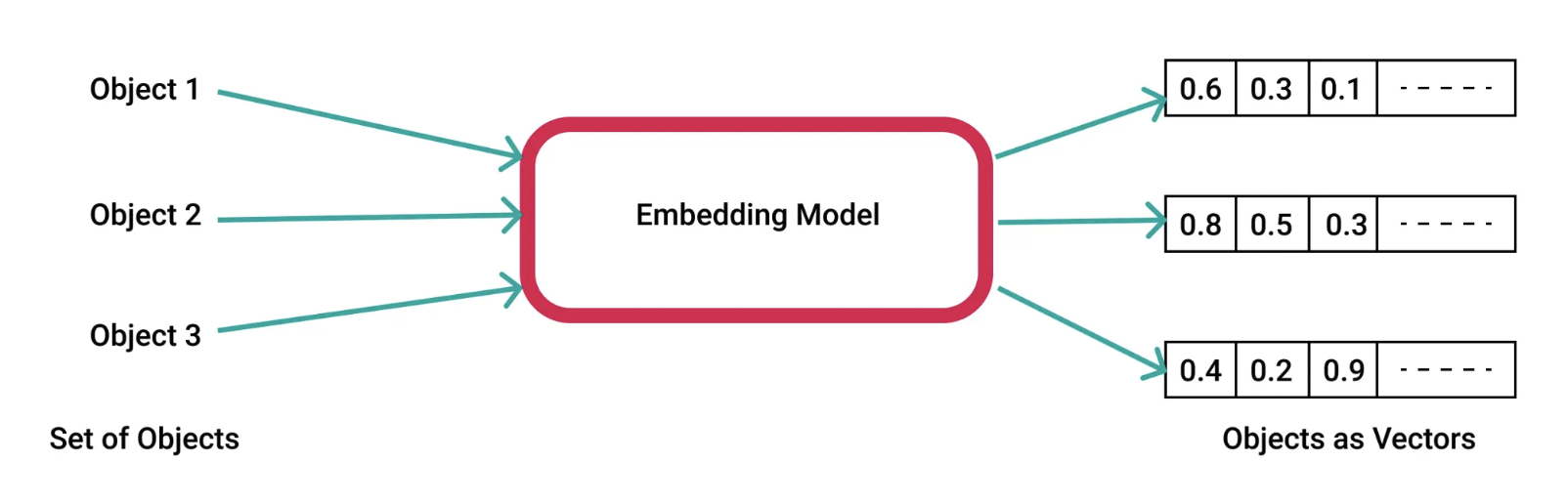
What are Vector Embeddings | Pinecone
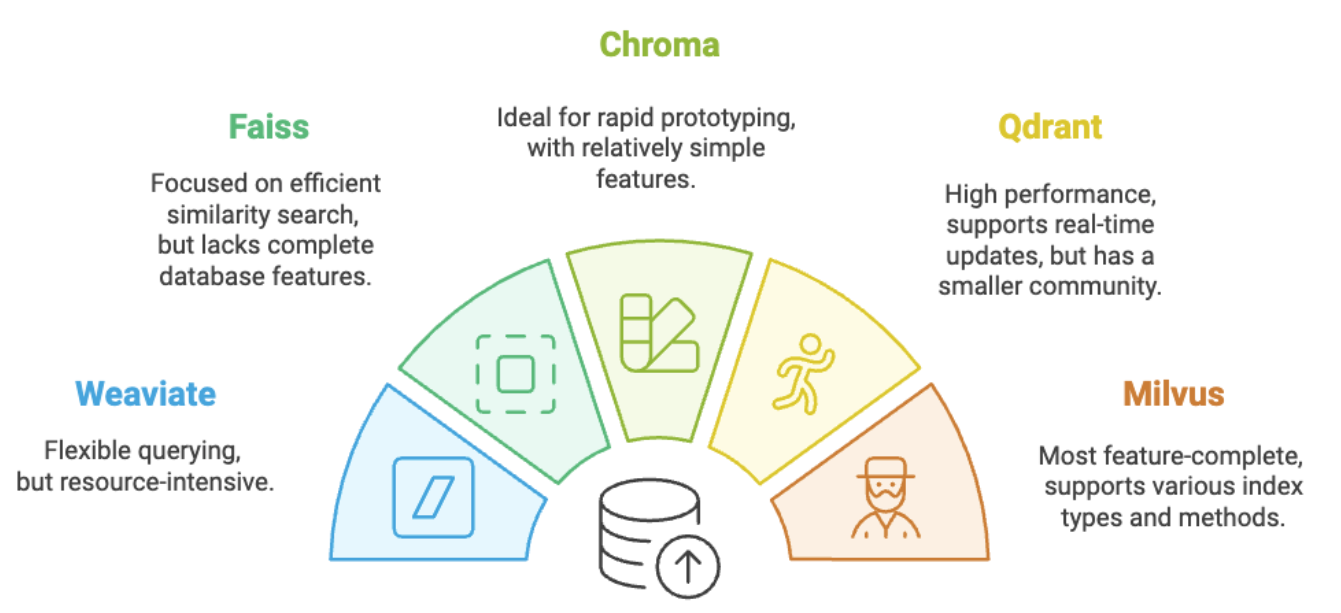
Vector Databases
向量資料庫儲存嵌入向量及其元數據,支援通過索引及近似最近鄰(ANN)方法高效檢索與查詢相關的文檔。有四個關鍵標準
- 多種索引類型(Multiple Index Types):提供靈活性,根據數據特性與應用場景優化檢索。
- 支持億級別的向量數據(Billion-Scale Vector Support):處理大型數據集時必需。
- 混合檢索(Hybrid Search):將向量檢索與傳統關鍵詞檢索相結合,提高檢索準確性。
- 雲原生功能(Cloud-Native Capabilities):確保在現代雲基礎架構中的無縫集成、擴展性及管理。
向量資料庫 (Vector Database)
⇒ Weaviate、Faiss、Chroma、Qdrant 和 Milvus
Retrieval Methods
根據查詢和文檔之間的相似性,檢索模組從預先構建的語料庫中選擇最相關的文檔(top-k)
-> 生成模型使用這些檢索到的文檔來生成對應的回應
- 查詢重寫(Query Rewriting):
- 通過重寫查詢來改善其匹配相關文檔的能力。
- 基於 Rewrite-Retrieve-Read 框架,使用大型語言模型(LLM)來改寫查詢。
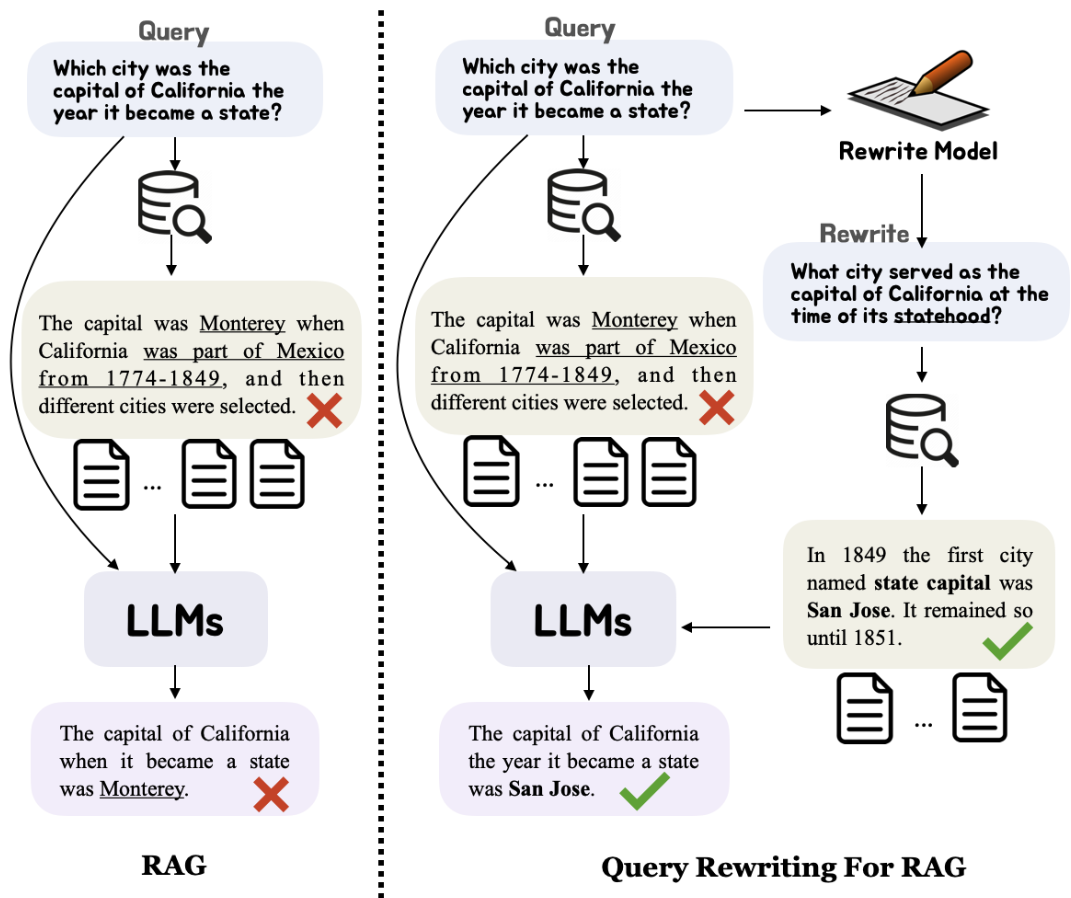
- 查詢分解(Query Decomposition):
- 將原始查詢分解為子問題,並基於子問題檢索相關文檔。
- 此方法更適合處理複雜查詢,但實現起來更具挑戰性。
- 虛擬文檔生成(Pseudo-documents Generation):
- 基於用戶查詢生成假設文檔,並使用這些文檔的嵌入向量進行檢索。
- 一個具代表性的實現是 HyDE 方法。
⇒ 基於詞彙的檢索(如 BM25)和向量檢索(如 Contriever)顯著提升了性能。
⇒ 這種混合方法利用詞彙檢索處理具體術語,並利用向量檢索處理語義相似性。
Result of Retrieval Methods
實比對效能:
- 監督方法的優勢:
- 在 TREC DL 2019 & 2020 的數據集上 Supervised Learning (e.g. HyDE, LLM-Embedder) > Unsupervised Learning
- Query Rewriting & Query Decomposition 效果有限
- Hybrid Search (混合搜尋) with HyDE:結合稀疏檢索 (e.g. BM25) 和密集檢索 (e.g. Embedding Model),較低的延遲和保持性能
- Hybrid Search : BM25 + Original embedding
Ranking Methods
目的在於提升檢索結果相關性,確保最相關文的在列表頂端,雖然更精準但也更耗時,增加查詢與頂層文件的相關性。
- DLM Reranking(基於深度語言模型的排序)
- 使用 DLMs 判斷 document 與 query 的相關性
- 預測 "True" / "False" -> 判斷 True 的機率排序
.png)
- TILDE Reranking(基於查詢詞概率的排序)
- 獨立計算每個查詢詞的概率來評估文檔分數
- Document Repacking 透過重組的方式嘗試提升效能
Summarization
在檢索後需要將內容進行摘要生成,但可能會面臨倒冗餘、不必要資訊或導致影響生成結果,且過長的提示會降低推理速度
- Extractive (抽取式摘要)
- 將文本分割為句子,按重要性打分後排序
- Abstractive(生成式摘要)
- 將多個資訊重組和改寫,生成連貫的摘要
實驗方法,使用三個基準數據集進行測試:NQ、TriviaQA 和 HotpotQA
- Recomp
- 同時支持抽取式和生成式摘要
- 抽取式部分選擇有用的句子,生成式部分將多個文檔的信息合成為連貫的摘要
- LongLLMLingua
- 專注於提取與查詢相關的關鍵信息
- 實驗中表現不如其他方法,但展現了較好的泛化能力
- Selective Context
- 識別並刪除上下文中的冗餘信息來提高LLM的效率
- 使用因果語言模型計算自信息量,對詞彙單元進行評估
- 支持比較基於查詢和非基於查詢的方法
使用「覆蓋分數」(Coverage Score)作為評估指標
[金融科技] 如何用AI撰寫高品質的文章(2) — 使用MongoDB結合向量資料庫與全文搜尋 - 人工智慧與財務分析 - Medium
RAG 框架
- Naïve RAG
- Advanced RAG
- CRAG, Corrective RAG
- MiniRAG - Towards Extremely Simple Retrieval-Augmented Generation
- LightRAG - Simple and Fast Retrieval-Augmented Generation
Related Work
- ACL Ready - RAG Based Assistant for the ACL Checklist
- How to Parse the Paper Chunking.
- Call Me When Necessary - LLMs can Efficiently and Faithfully Reason over Structured Environments
- 自我修正機制