Token
AI 讀取的每個資訊都是數字,有兩個概念 Token ID, Embedding 向量
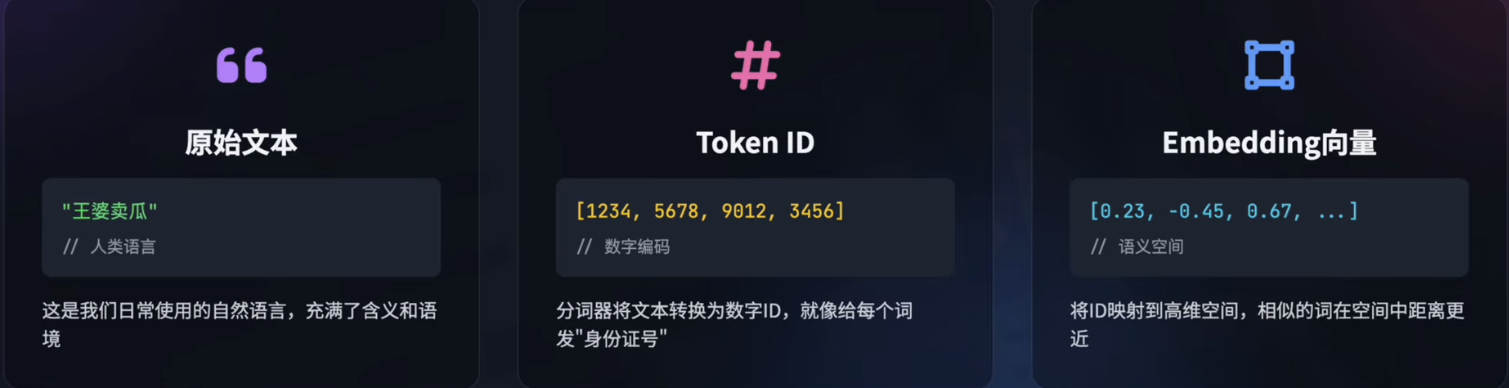
所謂的 Token 就是模型讀取的最小單位
是模型輸出和輸入的方式,我們透過自然語言輸入的內容模型其實看不懂,模型所理解的是一串數字,所以必須先透過 Tokenizier(分詞器) 先進行翻譯
GPT-4o & GPT-4o mini 分詞器
原文:
你好,我是一個工程師
未來想做AI工程師
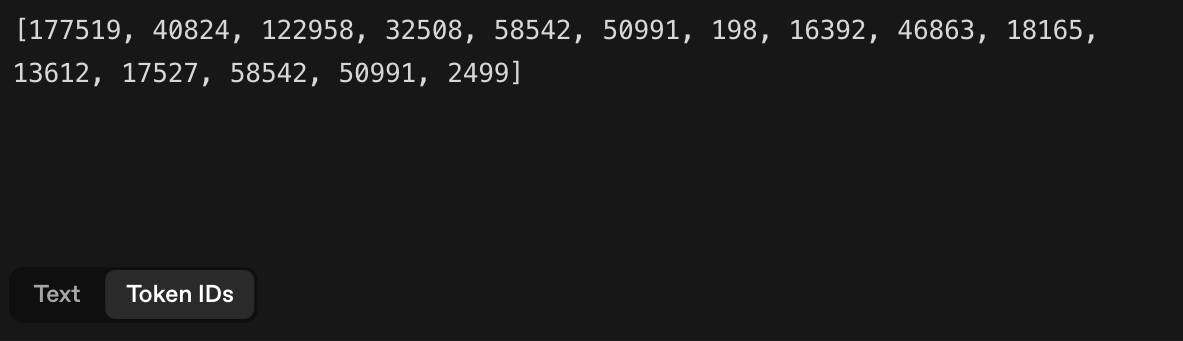
以下的 Tokens 為 15 , Characters 為 23
仔細看可以發現是以一組一組為單位的 Token

而模型理解的是這樣一段數字
包含標點符號都有可能被認為是 Tokens
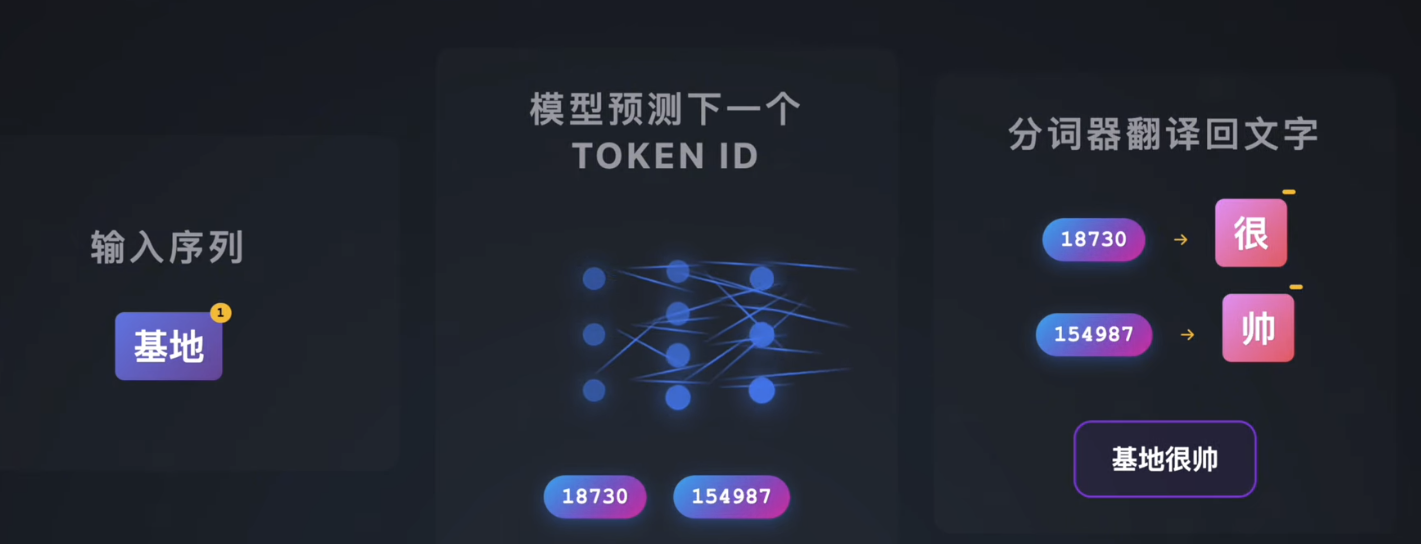
圖示:輸入序列在預測下一個 TokenID
OpenAI Platform - Learn about language model tokenization
⇒ 為什麼不是每一個字都拆解出來?
一句話太長,成本太高!但是不會有不認識的詞語了

不過還是可以根據不同模型的專任去改變,例如:
- GPT-4 為了程式碼,會將 4 個空格視為一個 Token
- DeepSeek Coder 會將數字的規律都將數字變成字節(個位數)開始學
- ChatGPT 聊天機器人會加上
<|user|>,<|assistatn|>用於判斷哪個是用戶輸入和輸出
但若有語意問題呢?
⇒ Embedding (嵌入) 這就是 AI 理解世界的方式