Advanced RAG
RAG, Retrieval-Augmented Generation
結合了傳統的語言模型生成和資料檢索過程,讓模型在生成答案前能夠參考到相關的外部資訊
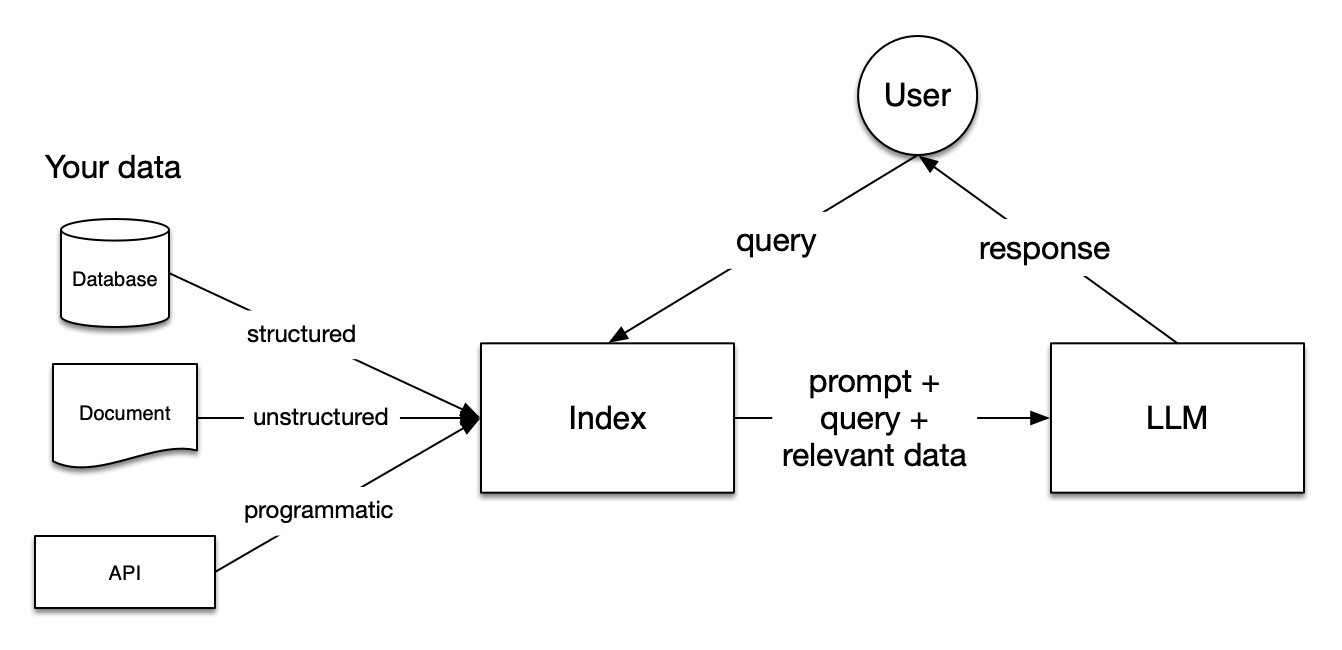
進階檢索方法,涵蓋兩種進階檢索方法:
- 句子窗口檢索(sentence window retrieval):
將文檔切割成更細粒度(句子或句群),檢索時以最相關句子為核心,再加入鄰近上下文,讓 LLM 能得到更完整語境,助於理解和利用文本中的語境 - 自動合併檢索(auto-merging retrieval):
立層次結構(節點樹),當多個子節點與查詢相關時,自動合併為更高層父節點文本,以生成更連貫、資訊量更大的上下文內容,可以動態地提供更完整的文本片段,有助於解決複雜的查詢
Day25 GAI爆炸時代 - Advanced RAG 介紹 - iT 邦幫忙::一起幫忙解決難題,拯救 IT 人的一天
Naïve RAG (單純 chunk → embedding → top-k → LLM)在召回不準、上下文不足、答案不穩定時會明顯撞牆,因此引入「不改 LLM、優化檢索與上下文組裝」的方法
常見瓶頸:
- chunk 切太粗 / 太碎 → 語義不完整
- embedding 無法直接對齊使用者問法
- top-k chunk 各自相關,但「合起來沒故事」
- LLM 容易忽略中間段落(lost in the middle)
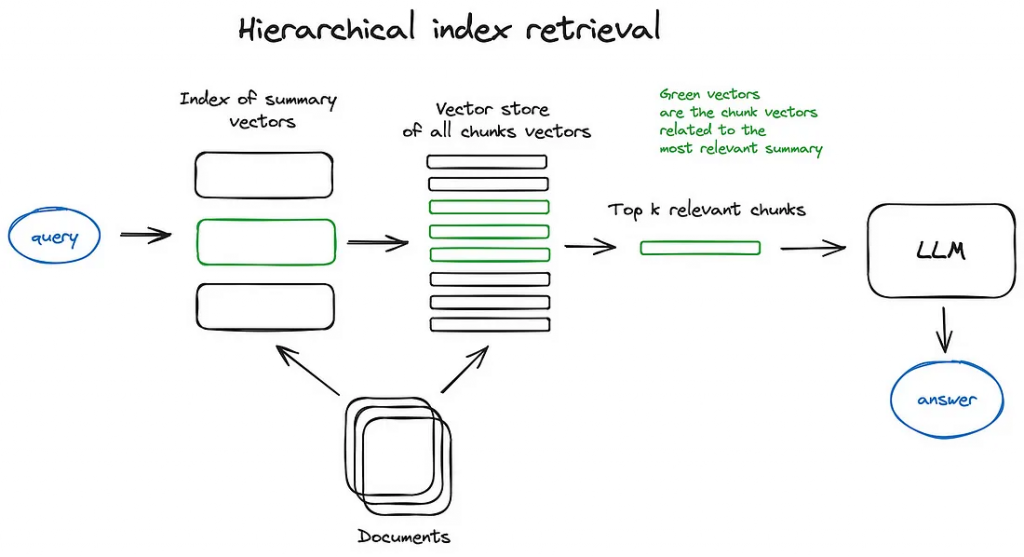
Hierarchical Indices(階層索引)
- 文件層(Document-level)
每份 document → LLM 產生 summary → embedding → 向量索引 - chunk 層
只對「summary 相近的文件」做 chunk search
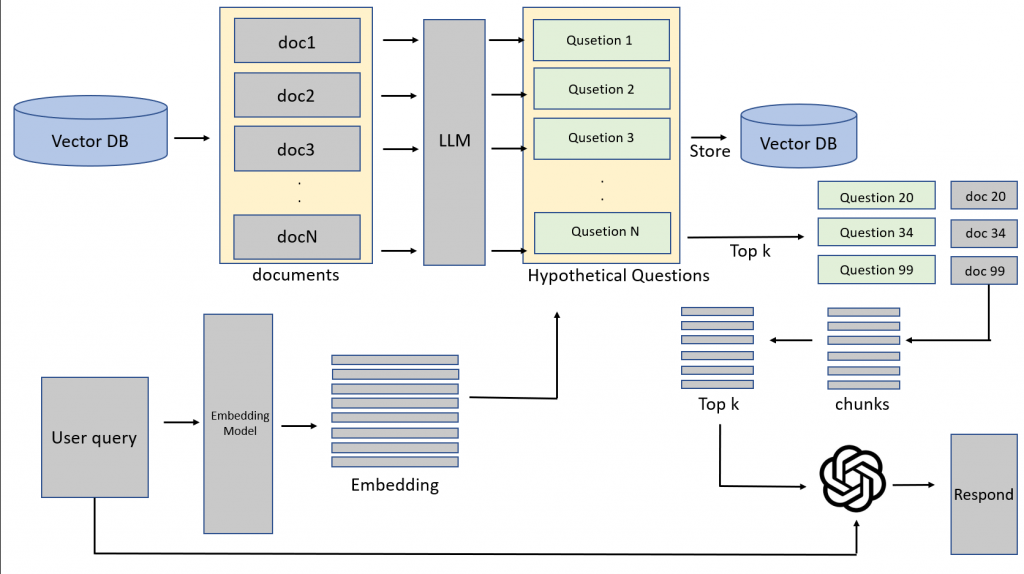
Hypothetical Questions(HQ)
做法:
- 每個 chunk → LLM 生成「可能會被問的問題」
- 用 問題 embedding 當索引
- user query ↔ HQ 比對 → 回到 chunk
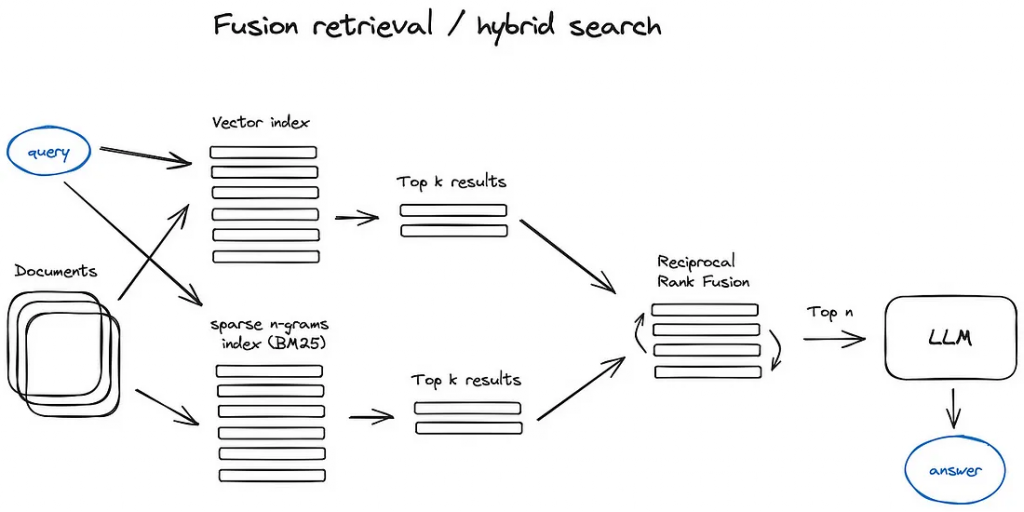
Fusion Retrieval(Hybrid Search)
做法:
- Dense(vector search) + Sparse(BM25)
- 用 RRF(Reciprocal Rank Fusion) 合併排名
[Building and Evaluating Advanced RAG Applications。建立與評估進階RAG] - HackMD
Day25 GAI爆炸時代 - Advanced RAG 介紹 - iT 邦幫忙::一起幫忙解決難題,拯救 IT 人的一天