Call Me When Necessary - LLMs can Efficiently and Faithfully Reason over Structured Environments
提出框架 Reasoning-Path-Editing (Readi):
旨在讓大型語言模型(LLMs)能夠在結構化環境(如知識圖譜和表格)中高效且準確地進行推理。
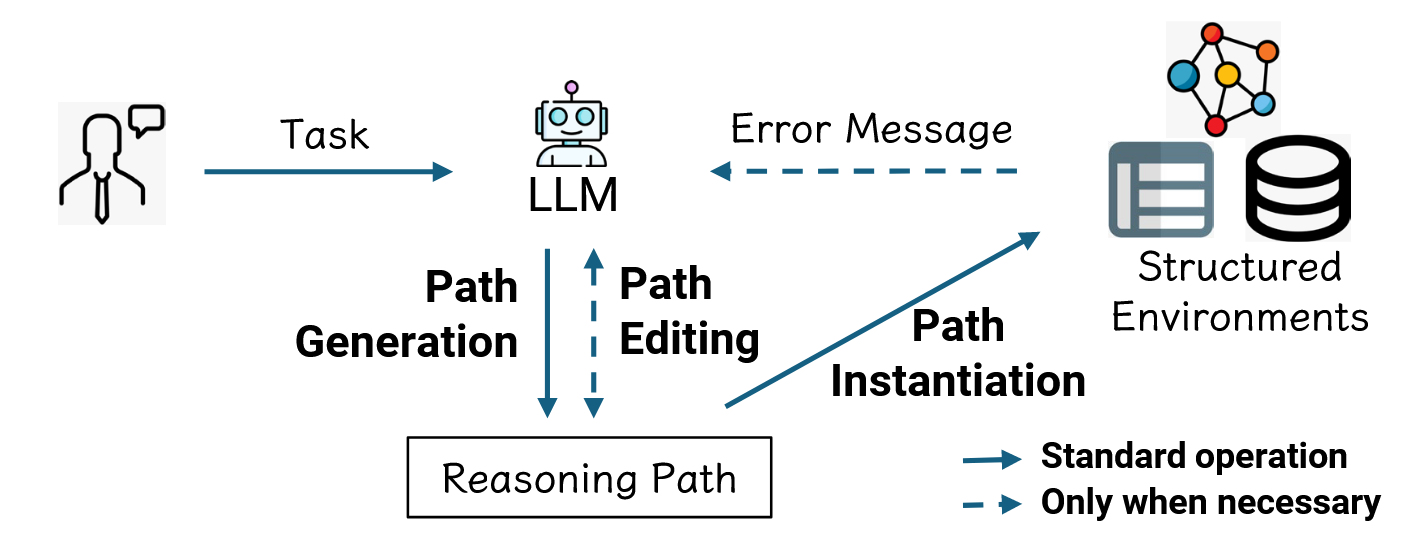
簡單來說步驟就是:
- 一步生成推理路徑 (Path Generation)
- 傳統的做法是逐步執行,也就是做完第一步再問第二部 (每一步都要調用模型,花費時間,也容易累積錯誤)
- 路徑實例化 (Path Instantiation)
- 使用生成的路徑直接進行資料匹配
- 錯誤修正 (Error Message)
- 只在必要時進行,節省時間,例如查詢資料為空等等,重新生成查找方法
特點:
- 規劃整體路徑:模型一開始就有全局觀,不會像傳統方法一樣「走一步看一步」,減少累積錯誤的風險。
- 即時修正錯誤:遇到障礙時,利用反饋來修正推理,保持結果準確性。
- 少調用模型:僅在需要修正時才額外調用,整體調用次數大大降低。
Related Work
傳統做法
- 透過一些方法讓模型自我檢查錯誤,進行 自我修正
- 這倚賴「內在知識庫」改進空間有限
Cite
Such methods achieve limited improvement, since they rely only on the intrinsic knowledge of LLMs, without any access to the environment
- 透過環境反饋得知新的新錯誤訊息或是新的知識來進行修正計劃,比起自我糾正更精確地改進
- TEACHING LARGE LANGUAGE MODELS TO SELFDEBUG By Google DeepMind
根據上述文獻,進行優化:
- 收集反饋進行推理:
- 錯誤發生的位置
- 部分完成的推理結果
- 和錯誤相關的數據(比如知識圖譜中的關聯資訊)
- 利用反饋精準定位問題,比完全靠內部知識修正更有針對性,也更有效